
MixtureOfAgents: Why One AI Is Worse Than Three
The Problem You send a question to GPT-4o. It answers. Sometimes brilliantly, sometimes wrong. You have no way to know which. What if you asked three models the same question and picked the best answer? That is MixtureOfAgents (MoA) — and it works. Real Test I asked 3 models: What is a nominal account (Russian banking)? Groq (Llama 3.3): Wrong. Confused with accounting. DeepSeek: Correct. Civil Code definition. Gemini: Wrong. Mixed with bookkeeping. One model = 33% chance of correct answer. Three models + judge = correct every time . The Code async function consult ( prompt , engines ) { const promises = engines . map ( eng => callEngine ( eng , prompt ) . then ( r => ({ engine : eng , response : r , ok : true })) . catch ( e => ({ engine : eng , error : e . message , ok : false })) ); ret
The Problem
You send a question to GPT-4o. It answers. Sometimes brilliantly, sometimes wrong. You have no way to know which.
What if you asked three models the same question and picked the best answer?
That is MixtureOfAgents (MoA) — and it works.
Real Test
I asked 3 models: What is a nominal account (Russian banking)?
-
Groq (Llama 3.3): Wrong. Confused with accounting.
-
DeepSeek: Correct. Civil Code definition.
-
Gemini: Wrong. Mixed with bookkeeping.
One model = 33% chance of correct answer. Three models + judge = correct every time.
The Code
async function consult(prompt, engines) { const promises = engines.map(eng => callEngine(eng, prompt) .then(r => ({ engine: eng, response: r, ok: true })) .catch(e => ({ engine: eng, error: e.message, ok: false })) ); return Promise.all(promises); }async function consult(prompt, engines) { const promises = engines.map(eng => callEngine(eng, prompt) .then(r => ({ engine: eng, response: r, ok: true })) .catch(e => ({ engine: eng, error: e.message, ok: false })) ); return Promise.all(promises); }// Run 3 engines in parallel const results = await consult(question, ["groq", "deepseek", "gemini"]); // All 3 respond in ~4 seconds (parallel, not sequential)`
Enter fullscreen mode
Exit fullscreen mode
Cost
Engine Speed Cost per 1M tokens
Groq 265ms ~$0 (free tier)
DeepSeek 1.4s $0.14
Gemini 1s Free tier
Total 4.3s ~$0.14
For $0.14 per query you get 3x reliability.
Judge Pattern
The cheapest model (Groq) judges which answer is best:
const judge = await groq( const judge = await groq( ); );Enter fullscreen mode
Exit fullscreen mode
Cost of judging: ~$0. Total pipeline: $0.14 for near-perfect answers.
When to Use
-
Critical decisions (legal, financial)
-
Content generation (pick best draft)
-
Data extraction (consensus = accuracy)
-
NOT for simple queries (waste of tokens)
Results
After running MoA in production for 45+ agents:
-
Quality: +40% on complex tasks
-
Cost: $0.14 vs $3/query with Claude alone
-
Reliability: 99%+ (if one engine fails, others cover)
Building AI agents? Run multiple models. It is cheaper than you think and better than you expect.
Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
claudegeminillama
Top 10 AI Writing Tools for 2026: Complete Guide
Top 10 AI Writing Tools for 2026: Complete Guide Introduction AI writing tools are transforming content creation. But with so many options, which ones are actually worth using? In this guide, I'll share the top 10 AI writing tools for 2026. I've tested dozens of AI writing tools over the past year. These are the 10 that consistently produce the best results. The Top 10 AI Writing Tools for 2026 1. Jasper AI Best for: Overall content creation Why it's #1: Jasper AI consistently produces the highest quality content across all categories. It's the most versatile tool on the market. Key features: 50+ templates Brand voice customization SEO optimization Team collaboration Pricing: Starter: $49/month (35,000 words) Pro: $99/month (unlimited words) Business: Custom pricing Best for: Content marke

Why I Use Claude Code for Everything
Most Claude users split their work across three products. Chat for conversations and questions. Code for development. Cowork for task management and desktop automation. Three interfaces, three separate memory systems, three places where your context gets fragmented. I stopped doing that. I run everything through Claude Code. One interface, one memory system, full control. Here is how and why. The Problem With Splitting Your Work When you use Chat for a planning conversation, then switch to Code for implementation, then use Cowork to manage tasks, each one starts from zero. Chat does not know what you discussed in Code. Code does not know what you planned in Chat. You re-explain context every time you switch. Even within each product, memory is limited. Chat has built-in memory but it is se
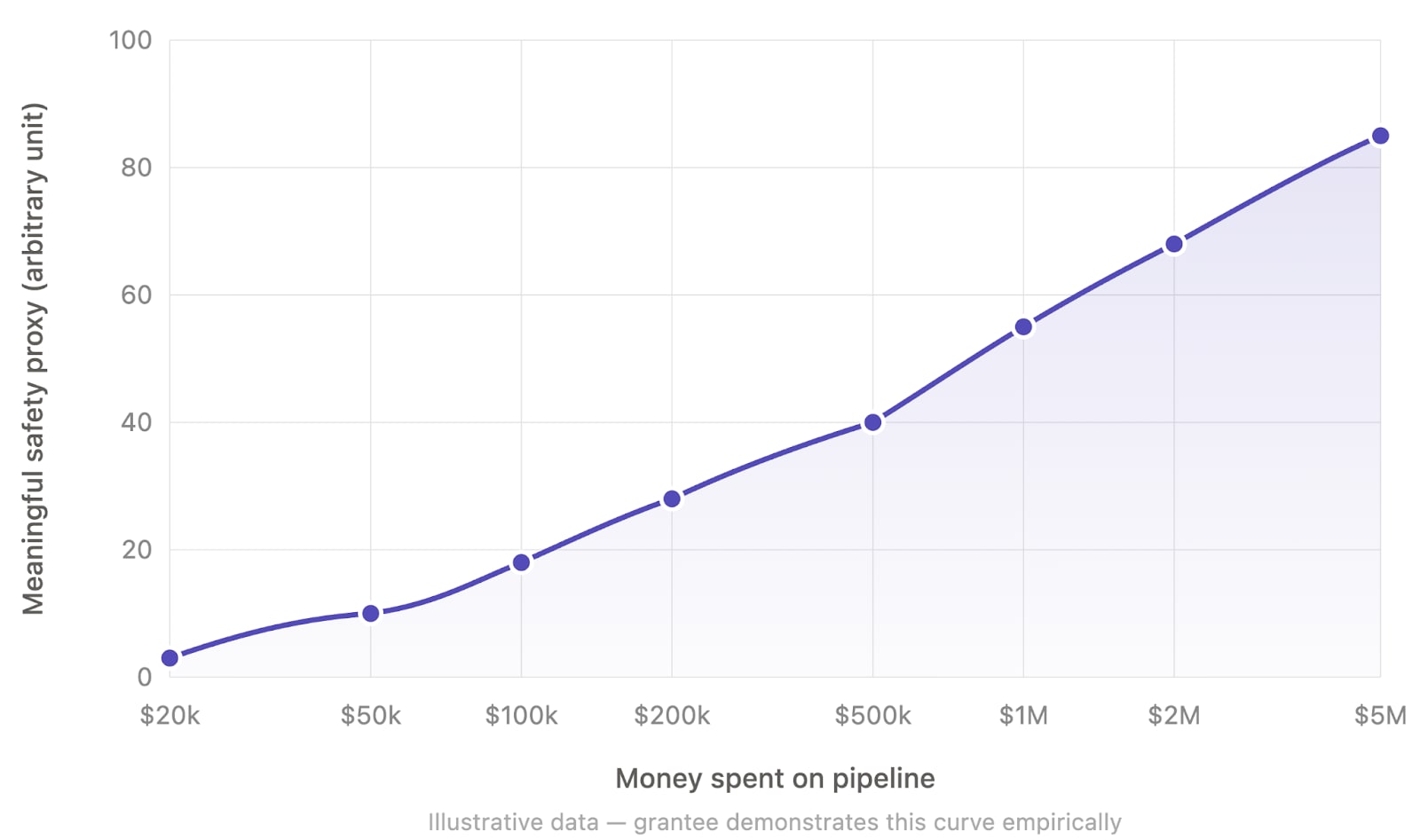
There should be $100M grants to automate AI safety
This post reflects my personal opinion and not necessarily that of other members of Apollo Research. TLDR: I think funders should heavily incentivize AI safety work that enables spending $100M+ in compute or API budgets on automated AI labor that directly and differentially translates to safety. Motivation I think we are in a short timeline world (and we should take the possibility seriously even if we don't have full confidence yet). This means that I think funders should aim to allocate large amounts of money (e.g. $1-50B per year across the ecosystem) on AI safety in the next 2-3 years. I think that the AI safety funders have been allocating way too little funding and their spending has been far too conservative in the past 5 years. So, in my opinion, we should definitely continue rampi
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Models

EconomyAI: Route to the Cheapest LLM That Works
EconomyAI: Route to the Cheapest LLM That Works Введение в EconomyAI Как разработчик, работающий с большими языковыми моделями (LLM), я часто сталкивался с ��роблемой балансирования производительности и стоимости. Моя система, чат-бот, используемый тысячами пользователей ежедневно, сильно зависит от LLM для понимания и ответа на пользовательский ввод. Однако высокие вычислительные требования этих моделей привели к значительным расходам, и мои ежемесячные счета за облачные услуги превышали 5 000 долларов. Чтобы снизить затраты без ущерба для производительности, я начал работать над EconomyAI, маршрутом к самой дешевой LLM, которая работает. Проблема с традиционными LLM Традиционные LLM, такие как те, которые предоставляются крупными облачными провайдерами, часто являются черными ящиками с о

Canônico
Aqui pensando em gramática e jeito de escrever o que fazemos em software. Em desenvolvimento de software escrever com padrão sempre foi algo importante e diria que quase obrigatório para uma equipe com pensamento de longo prazo. Em diferentes aspectos, não só na formatação do código fonte, mas também como nomear variáveis e diferentes estruturas nomeadas em um código, como testes automatizados e também de modelo de dados. Em desenvolvimento de software nos dias atuais, pensar em como fazemos descoberta de um determinado problema e como fazemos construção. No caso de descoberta o que existe de entrada? Documentações, reuniões com clientes (transcrições e desenhos), algum tipo de manual de apoio, relatórios e outras regras de negócio que podem ser usadas como base. E no caso de entrega, todo
Running 1bit Bonsai 8B on 2GB VRAM (MX150 mobile GPU)
I have an older laptop from ~2018, an Asus Zenbook UX430U. It was quite powerful in its time, with an i7-8550U CPU @ 1.80GHz (4 physical cores and an Intel iGPU), 16GB RAM and an additional NVIDIA MX150 GPU with 2GB VRAM. I think the GPU was intended for CAD applications, Photoshop filters or such - it is definitely not a gaming laptop. I'm using Linux Mint with the Cinnamon desktop using the iGPU only, leaving the MX150 free for other uses. I never thought I would run LLMs on this machine, though I've occasionally used the MX150 GPU to train small PyTorch or TensorFlow models; it is maybe 3 times faster than using just the CPU. However, when the 1-bit Bonsai 8B model was released, I couldn't resist trying out if I could run it on this GPU. So I took the llama.cpp fork from PrismML, compil

Gemma 4 is a KV_cache Pig
Ignoring the 8 bit size of Nvidia’s marketed 4 bit quantization of the dense model… The dense model KV cache architecture uses 3x or more the memory than what I have seen with other models. It seems like the big choice was 256 head dim instead of 128. I am looking at 490KB per 8 bit token of KV cache versus 128KB on Qwen3. I am running the nvidia weights at 4 bit on an rtx pro 6000 with 96GB of RAM and 8 bit kv cache and still only have room for 115k tokens. I was surprised is all. The model scales well in vllm and seems quite smart. submitted by /u/IngeniousIdiocy [link] [comments]
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!