
Do We Need Bigger Models for Science? Task-Aware Retrieval with Small Language Models
Hey there, little scientist! 🚀
Imagine you have a super-duper smart robot friend. This robot helps grown-ups learn new things about the world, like how plants grow or why stars twinkle.
Sometimes, these robots are super-duper big, like a giant castle! They know everything because they've read all the books. But big castles are hard to move around.
This story is about asking: "Do we always need a giant castle robot?" 🤔
Maybe we can have a smaller, clever robot! This clever robot has a special trick: it knows exactly where to look in its library of books to find the right answer super fast. It's like having a magic map to find the treasure! 🗺️✨
So, the grown-ups found out that sometimes, a small, clever robot with a good map can do almost as good a job as the giant castle robot! Isn't that cool? 🎉
arXiv:2604.01965v1 Announce Type: new Abstract: Scientific knowledge discovery increasingly relies on large language models, yet many existing scholarly assistants depend on proprietary systems with tens or hundreds of billions of parameters. Such reliance limits reproducibility and accessibility for the research community. In this work, we ask a simple question: do we need bigger models for scientific applications? Specifically, we investigate to what extent carefully designed retrieval pipelines can compensate for reduced model scale in scientific applications. We design a lightweight retrieval-augmented framework that performs task-aware routing to select specialized retrieval strategies based on the input query. The system further integrates evidence from full-text scientific papers an
View PDF HTML (experimental)
Abstract:Scientific knowledge discovery increasingly relies on large language models, yet many existing scholarly assistants depend on proprietary systems with tens or hundreds of billions of parameters. Such reliance limits reproducibility and accessibility for the research community. In this work, we ask a simple question: do we need bigger models for scientific applications? Specifically, we investigate to what extent carefully designed retrieval pipelines can compensate for reduced model scale in scientific applications. We design a lightweight retrieval-augmented framework that performs task-aware routing to select specialized retrieval strategies based on the input query. The system further integrates evidence from full-text scientific papers and structured scholarly metadata, and employs compact instruction-tuned language models to generate responses with citations. We evaluate the framework across several scholarly tasks, focusing on scholarly question answering (QA), including single- and multi-document scenarios, as well as biomedical QA under domain shift and scientific text compression. Our findings demonstrate that retrieval and model scale are complementary rather than interchangeable. While retrieval design can partially compensate for smaller models, model capacity remains important for complex reasoning tasks. This work highlights retrieval and task-aware design as key factors for building practical and reproducible scholarly assistants.
Comments: Accepted at NSLP@LREC 2026
Subjects:
Information Retrieval (cs.IR); Artificial Intelligence (cs.AI); Computation and Language (cs.CL); Digital Libraries (cs.DL)
Cite as: arXiv:2604.01965 [cs.IR]
(or arXiv:2604.01965v1 [cs.IR] for this version)
https://doi.org/10.48550/arXiv.2604.01965
arXiv-issued DOI via DataCite (pending registration)
Submission history
From: Michael Färber [view email] [v1] Thu, 2 Apr 2026 12:28:51 UTC (252 KB)
Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
modellanguage modelannounce

How to Build a Netflix VOID Video Object Removal and Inpainting Pipeline with CogVideoX, Custom Prompting, and End-to-End Sample Inference
In this tutorial, we build and run an advanced pipeline for Netflix’s VOID model. We set up the environment, install all required dependencies, clone the repository, download the official base model and VOID checkpoint, and prepare the sample inputs needed for video object removal. We also make the workflow more practical by allowing secure terminal-style [ ] The post How to Build a Netflix VOID Video Object Removal and Inpainting Pipeline with CogVideoX, Custom Prompting, and End-to-End Sample Inference appeared first on MarkTechPost .
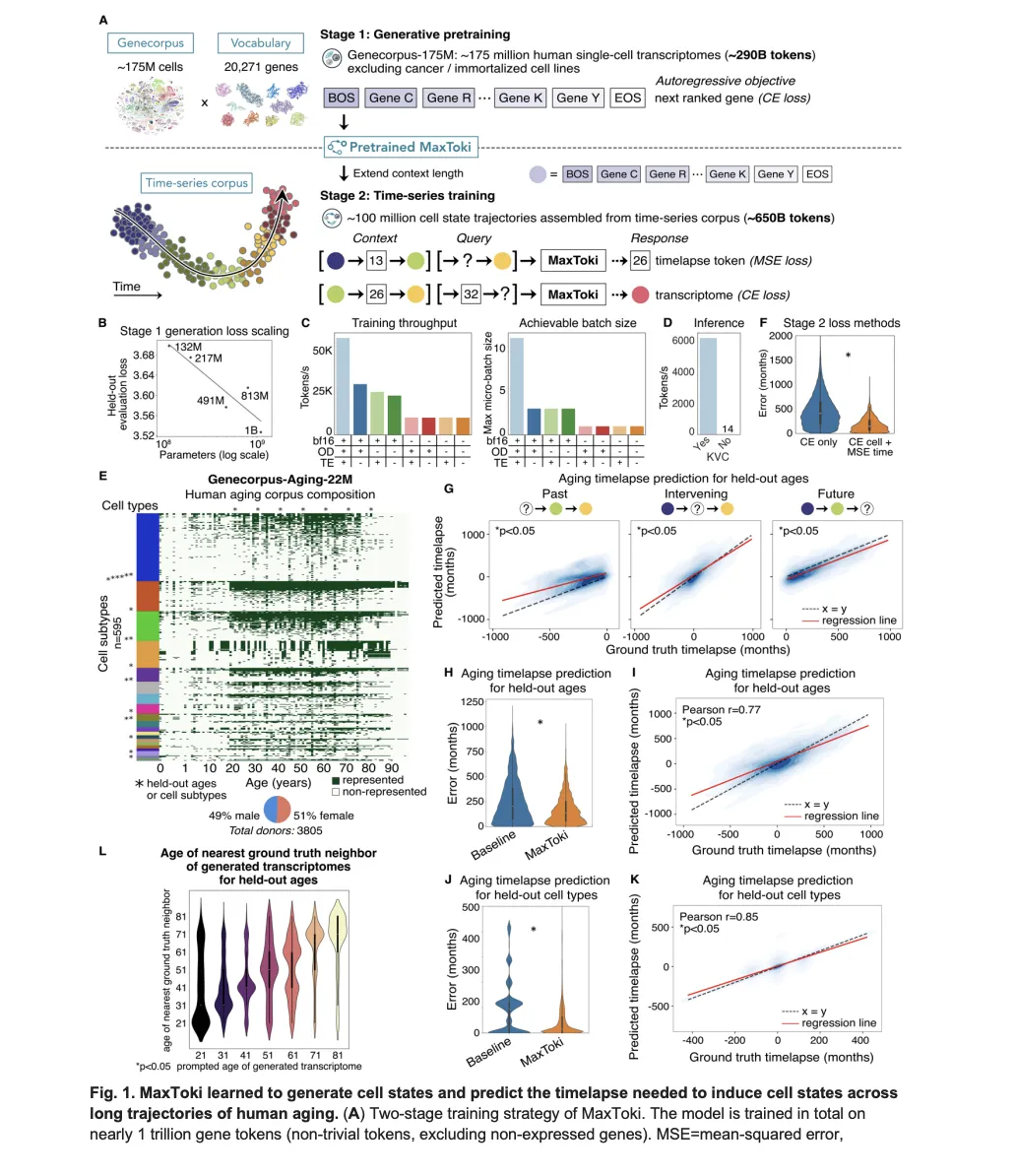
Meet MaxToki: The AI That Predicts How Your Cells Age — and What to Do About It
Most foundation models in biology have a fundamental blind spot: they see cells as frozen snapshots. Give a model a single-cell transcriptome — a readout of which genes are active in a cell at a given moment — and it can tell you a lot about what that cell is doing right now. What it [ ] The post Meet MaxToki: The AI That Predicts How Your Cells Age — and What to Do About It appeared first on MarkTechPost .
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.



Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!