

v0.16.0
Axolotl v0.16.0 Release Notes We’re very excited to share this new packed release. We had ~80 new commits since v0.15.0 (March 6, 2026). Highlights Async GRPO — Asynchronous Reinforcement Learning Training ( #3486 ) Full support for asynchronous Group Relative Policy Optimization with vLLM integration. Includes async data producer with replay buffer, streaming partial-batch training, native LoRA weight sync to vLLM, and FP8 compatibility. Supports multi-GPU via FSDP1/FSDP2 and DeepSpeed ZeRO-3. Achieves up to 58% faster step times (1.59s/step vs 3.79s baseline on Qwen2-0.5B). Optimization Step Time Improvement Baseline 3.79s — + Batched weight sync 2.52s 34% faster + Liger kernel fusion 2.01s 47% faster + Streaming partial batch 1.79s 53% faster + Element chunking + re-roll fix (500 steps)
Axolotl v0.16.0 Release Notes
We’re very excited to share this new packed release. We had ~80 new commits since v0.15.0 (March 6, 2026).
Highlights
Async GRPO — Asynchronous Reinforcement Learning Training (#3486)
Full support for asynchronous Group Relative Policy Optimization with vLLM integration. Includes async data producer with replay buffer, streaming partial-batch training, native LoRA weight sync to vLLM, and FP8 compatibility. Supports multi-GPU via FSDP1/FSDP2 and DeepSpeed ZeRO-3.
Achieves up to 58% faster step times (1.59s/step vs 3.79s baseline on Qwen2-0.5B).
Optimization Step Time Improvement
Baseline 3.79s —
-
Batched weight sync 2.52s 34% faster
-
Liger kernel fusion 2.01s 47% faster
-
Streaming partial batch 1.79s 53% faster
-
Element chunking + re-roll fix (500 steps) 1.59s 58% faster
ScatterMoE + LoRA Fused Triton Kernels (#3513)
Custom fused Triton kernels for training MoE models with LoRA adapters. By fusing the base expert matmul and LoRA computation into a single kernel pass, these kernels achieve up to 15x faster forward passes and 40x less activation memory vs the eager baseline.
Implementation detail
Key innovations include atomic-free split backward kernels (11x faster dA/dB gradients), autotunable tile sizes, fused gather backward (eliminates intermediate grouped-X buffer when workload is small), selective NF4 dequantization (only dequantizes routed experts - up to ~97% weight memory reduction per layer at short sequences where few experts are activated, though the savings diminish at longer contexts as most experts see at least one token), and H200/B200 register pressure tuning.
SonicMoE Fused LoRA (#3519)
LoRA support for SonicMoE (CUTLASS-based MoE kernels for Hopper/Blackwell GPUs).
This results in upto 1.45x speedup and 30% reduction over grouped_mm baseline on a 1xH100 SXM GPU (Qwen3.5-35B-A3B 8-bit LoRA tuning).
GRPO Flattening & Packing (#3552)
Enables batch flattening and sample packing for GRPO training, improving token efficiency and training throughput (~10%).
Flash Attention 4 support (#3481)
Support for Flash Attention 4 on Hopper and Blackwell GPUs with automatic fallback to FA2/3 depending on hardware.
We found improvements mainly on higher sequence lengths and on Blackwell GPUs.
NeMo Gym Integration (#3516)
Full integration with NVIDIA NeMo Gym for single-turn and multi-turn RL training. Re-use existing environments in Axolotl now! https://github.com/NVIDIA-NeMo/Gym
Implementation detail
Single-turn mode calls /verify endpoints for deterministic rewards (math, logic). Multi-turn mode delegates generation to a NeMo Gym agent server that orchestrates the full agentic loop — the model generates tool calls, the agent executes them against environment servers, feeds results back, and repeats until completion. An env_mask separates model-generated tokens (trained on) from tool results (masked out), and IS correction handles the logprob mismatch between agent-side generation and the training policy. Combined with async_prefetch, generation and training overlap for ~3x throughput on multi-turn tasks.
Energy-Based Fine-Tuning (EBFT) (#3527)
Novel RL training method that matches generated completions to ground-truth feature embeddings without requiring external reward models. Supports structured (vLLM) and strided (single GPU) modes.
Performance & Kernel Optimizations
- Custom Triton Kernels for RL (#3510) — Fused Triton kernels for entropy_from_logits (single-pass online algorithm) and selective_log_softmax (fused forward+backward). Both avoid materializing the full [B, L, V] softmax intermediate. Benchmarked on Qwen vocab (V=151,936), RTX 5090:
entropy_from_logits: 5.2x faster, near-zero memory overhead (0.2 MB vs 120 MB); on non-contiguous tensors: 7.3x faster, saves up to 10 GB by avoiding .contiguous() copy selective_log_softmax: 2.9x faster forward, 3.2x faster fwd+bwd, memory reduced from ~5 GB to <0.2 MB (at B=8, L=2048) — the original OOMs at B=16 where Triton succeeds
-
LoRA Kernel Enhancements (#3528) — Extended LoRA kernels to support bias, dropout, DoRA, and embeddings with FSDP2 compatibility — making them production-ready for all LoRA configurations.
-
Liger Kernels for Qwen 3.5 (#3531) — Fused RMSNorm + gated activation kernels for Qwen 3.5 and Qwen 3.5 MoE.
-
Auto TF32 (#3473) — Automatically enables TF32 matmul/cuDNN when hardware supports it.
-
Reduced Autotune Search Space (#3525) — Faster kernel autotuning startup.
New Features
-
CPU Layer Offloading (#3512) — Offload frozen decoder layers to CPU during LoRA training, streaming to GPU only during forward/backward. Dramatically reduces VRAM usage for large models.
-
Multiple Custom Optimizers (#3457) — End-to-end support for Flash AdamW, Optimi AdamW, ADOPT AdamW, Muon, Dion, Schedule-Free AdamW, and CAME PyTorch.
-
Memory-Efficient LoRA Merging (#3095) — Iterate through weight bins without loading entire layers into memory, enabling merging of massive models on resource-constrained systems.
-
Custom MoE Routing (#3526) — Support for Ernie 4.5 MoE and Hunyuan V1 MoE custom routing strategies beyond standard softmax-topk.
-
Synthetic Benchmarking Datasets (#3518) — Built-in synthetic datasets for benchmarking and testing training pipelines.
-
MX Quantization-Aware Training (QAT) (#3553) — Support for MX format QAT with torchao integration, including state dict hooks for saving dequantized safetensors from transformers.
-
dtype Propagation for torchao (#3569) — Proper dtype handling through torchao quantization and optimizer paths.
-
Lazy Trainer Loading (#3568) — Lazy-load trainer classes to avoid unnecessary imports, improving startup time.
Documentation
- Greatly improved documentation for GRPO and Agents use (#3564) — New dedicated guides for GRPO training, vLLM serving, training stability and monitoring, debugging, and choosing training methods. Adds agent-specific documentation and deduplicates content across pages.
Model & Framework Support
Deprecation
-
Deprecated torch 2.8.0 support (#3550)
-
Removed dead SDPA patches (#3488)
New Model Support
-
Mistral Small 4 (#3502)
-
Qwen 3.5 / Qwen 3.5 MoE (#3515, #3523, #3554)
-
NeMo Super (Nemotron-H) Support (#3508)
Updates
-
Transformers 5.4.0 (#3562)
-
lm-eval updated for Transformers v5 (#3571)
-
Torchao 0.17.0 (#3569)
-
Gemma 3 config fixes (#3500)
-
Docker builds for py312-cu128-torch2.9.1 (#3489)
Bug Fixes
-
Fixed high eval loss with sample packing (#3478)
-
Fixed double sequence partition with Context Parallelism (#3498)
-
Fixed DPO compatibility with transformers v0.29 (#3560)
-
Fixed Ray train crashing after succeeding (#3542)
-
Fixed race condition in patching checks (#3543)
-
Fixed token state JSON and Mistral tokenizer issue (#3522)
-
Fixed async model loading with quantized BNB models (#3477)
-
Fixed MoE quant patch for merge mismatches (#3483)
-
Fixed connection error handling for user whoami check (#3529)
-
Patches only applied when CUDA is available (#3561)
-
Fixed shell injection in modal CLI (#3487)
-
Fixed DPO tool role KeyError (#3217), dataset hash output_dir (#3303), config validators (#3538)
-
Added precompute_ref_log_probs to config schema (#3555)
-
Added troubleshooting note for GLM4 GGUF MTP mismatch (#3559)
-
Allow bf16 flag with deprecation warning (#3563)
Infrastructure
-
Scored rollouts dispatched to plugins with extended external plugin paths (#3549)
-
CI improvements: codecov informational only, better error handling (#3534, #3517)
-
Make CI fail GitHub Actions on test failures (#3517)
-
Consolidate routing behavior in ScatterMoE kernels (#3475)
-
roundup_power2_divisions no longer needed with newer PyTorch versions (#3540)
-
Logging cleanup (#3482)
-
Update pre-commit hooks (#3567)
-
Update README (#3503)
-
Docker: ubuntu user improvements for uv images (#3491, #3492, #3494, #3495, reverted #3496)
What We Tried (So You Don't Have To)
A few optimizations we prototyped but found little-to-no improvement — sharing so others can skip these rabbit holes:
-
Fused NF4 dequant inside the ScatterMoE Triton GEMM kernel — reads NF4-packed expert weights directly in the inner loop, avoiding the bf16 intermediate buffer entirely. Correctness-verified (zero numerical error), but 3x slower than the separate dequant + bf16 path. BnB's dequant kernel reads data linearly at full memory bandwidth (~1 TB/s), while the fused kernel's scattered byte addressing and per-element NF4 codebook lookups destroy memory coalescing.
-
Batched NF4 dequantization — concatenating gate_up + down_proj packed NF4 data into a single dequant call. Produced identical performance (1.00x) — the kernel is purely bandwidth-bound, so one large call = two smaller calls at the same total bytes.
-
Dequant buffer pool for NF4 MoE — pre-allocating reusable bf16 buffers to avoid 512 alloc/free cycles per step during NF4 expert dequantization. Reduced memory fragmentation from 20.9% to 4.2% and freed ~990 MiB, but wall-clock improvement was modest (~5%) since CUDA's caching allocator already handles the churn well in practice. Not shipped — the complexity wasn't worth the marginal gain.
-
LoRA layout conversion cache — caching the peft-to-ScatterMoE weight conversion (invalidated via PyTorch parameter _version counter) to avoid ~100 GB/step of allocation churn from repeated contiguous() calls. Similar story: measurable in profiler, marginal in wall-clock.
-
Adaptive split dispatch by expert count — automatically selecting between fused LoRA kernel (wins for many-expert models like Qwen3.5 E=256) and split dispatch with 3 base scatter2scatter calls (wins for few-expert models like Mixtral E=8 where SMEM pressure forces tiny tiles). Prototyped with an E <= 32 heuristic — showed 35% forward speedup on Mixtral. Not shipped yet due to the need for broader validation across model shapes.
-
Async weight sync for GRPO (background thread sync after deferred scores) — SLOWER than synchronous sync at start of produce_data, because queue drain at end has slower futures completion.
-
vLLM logprobs as old_per_token_logps in GRPO — using vLLM's sampling logprobs as the "old" policy logprobs to skip a forward pass. Completely broke learning (accuracy stayed at 0) because stale weights make the importance sampling ratio meaningless._
New Contributors
-
@Hadar01 made their first contribution in #3485
-
@Nero10578 made their first contribution in #3515
-
@OnePunchMonk made their first contribution in #3488
-
@BrownianNotion made their first contribution in #3560
-
@mariozupan made their first contribution in #3559
-
@joaquinhuigomez made their first contribution in #3555
-
@Edward-Zion-Saji made their first contribution in #3538
All Changes
-
bump dev version to 0.16.0.dev0 by @winglian in #3472
-
update setuptools so trl can be installed from main for nightlies by @winglian in #3471
-
add gpu correctness tests for scattermoe-lora by @winglian in #3474
-
load weights synchronously so they can be converted and not OOM by @winglian in #3477
-
fix: reduce permissions for preview docs CI by @NanoCode012 in #3480
-
builds for py312-cu128-torch2.9.1 by @winglian in #3489
-
swap around what we're building for docker by @winglian in #3490
-
use ubuntu user instead of root for uv docker images by @winglian in #3491
-
check ubuntu user and set uv python dir by @winglian in #3492
-
become the ubuntu user when root logs in by @winglian in #3494
-
preserve env for root -> ubuntu user by @winglian in #3495
-
Reverts commits 79908b3, 083c5a0, e1ff756, ff77fa2 by @winglian in #3496
-
moe quant patch for merge miss match by @ved1beta in #3483
-
chore: logging cleanup by @NanoCode012 in #3482
-
fix: high eval loss w/ sample packing by @ved1beta in #3478
-
fix: fix CONTRIBUTING.md placeholders, bare except clauses, and add convert.py tests by @Hadar01 in #3485
-
fix: explicit set workflow permission and move secrets to necessary by @NanoCode012 in #3484
-
feat: add FA4 by @NanoCode012 in #3481
-
feat: add Mistral Small 4 by @NanoCode012 in #3502
-
chore(doc): update readme by @NanoCode012 in #3503
-
automatically enable tf32 if supported by @winglian in #3473
-
consolidate behaviour of routing in scattermoe kernels by @winglian in #3475
-
fix: replace shell=True subprocess with argument list in modal CLI by @Hadar01 in #3487
-
Support for Async GRPO by @winglian in #3486
-
fix for flaky tests in lora ops kernels w autotune by @winglian in #3511
-
use custom triton kernels for entropy from logits and selective softmax by @winglian in #3510
-
make the CI fail GitHub Actions on test failures by @winglian in #3517
-
Scattermoe LoRA optimizations by @winglian in #3513
-
fix num_labels=1 test fail by @ved1beta in #3493
-
qwen docs + new config by @ved1beta in #3499
-
gemma fft configs by @ved1beta in #3500
-
nemotron config by @ved1beta in #3506
-
Fix double sequence partition during training with context-parallel by @lorenzbaraldi in #3498
-
Qwen3.5-MoE example config with lora_target_modules regex by @Nero10578 in #3515
-
cleanup: remove dead SDPA patches by @OnePunchMonk in #3488
-
fix: mistral small 4 post fix by @NanoCode012 in #3507
-
feat: add support and end-to-end tests for multiple custom optimizers by @OnePunchMonk in #3457
-
handle qwen3.5 moe loading by @winglian in #3523
-
reduce autotune search space by @winglian in #3525
-
fix token state json and mistral tokenizer issue by @winglian in #3522
-
support offloading layers to CPU by @winglian in #3512
-
synthetic datasets for benchmarking and testing by @winglian in #3518
-
fix: handle connection errors when checking user whoami by @winglian in #3529
-
liger support for qwen 3.5 and fused rmsnorm+gated by @winglian in #3531
-
feat: LoRA kernel support for bias, dropout, dora, embeddings by @winglian in #3528
-
increase rtol, codecov informational only, don't silently fail errors w curl by @winglian in #3534
-
post merge lora fixes for CI by @winglian in #3536
-
roundup_power2_divisions not needed with newer pytorch versions by @winglian in #3540
-
fix: robust handling of race condition on patching check by @winglian in #3543
-
EBFT: Matching Features, Not Tokens: Energy-Based Fine-Tuning of Language Models by @winglian in #3527
-
Revert "feat: move to uv first" by @NanoCode012 in #3544
-
Nemo gym integration by @winglian in #3516
-
Fix Ray train crashing after succeeding by @mhambre in #3542
-
feat: add custom routing support for ernie4_5_moe, and hunyuan_v1_moe by @OnePunchMonk in #3526
-
feat: merge-lora iterate through bins without loading by @ved1beta in #3095
-
dispatch scored rollouts to plugins, extend path for external plugins, better handle errors with vllm /reset_prefix_cache by @winglian in #3549
-
More minor RL fixes by @winglian in #3551
-
deprecate torch 2.8.0 support by @winglian in #3550
-
support flattening/packing for GRPO by @winglian in #3552
-
super nemo support by @ved1beta in #3508
-
DPO transformers v0.29 fixes by @BrownianNotion in #3560
-
bug-fix: only apply patches when CUDA is available by @kallewoof in #3561
-
upgrade transformers to 5.4.0 by @winglian in #3562
-
qwen3.5 configs by @ved1beta in #3554
-
allow bf16 flag but warn by @kallewoof in #3563
-
chore: update pre-commit hooks by @github-actions in #3567
-
Add troubleshooting note for GLM4 GGUF MTP mismatch by @mariozupan in #3559
-
Add precompute_ref_log_probs to config schema by @joaquinhuigomez in #3555
-
lazy load trainer classes to prevent unnecessary imports by @winglian in #3568
-
MX QAT patch by @ved1beta in #3553
-
fix: DPO tool role KeyError, dataset hash output_dir, config validators by @Edward-Zion-Saji in #3538
-
Fix lm-eval integration by @BrownianNotion in #3571
-
feat(docs): comprehensive improvement by @NanoCode012 in #3564
-
feat: add sonicmoe fused lora support by @NanoCode012 in #3519
-
upgrade torchao to 0.17.0 by @winglian in #3569
Full Changelog: v0.15.0...v0.16.0
Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
mistralmodellanguage model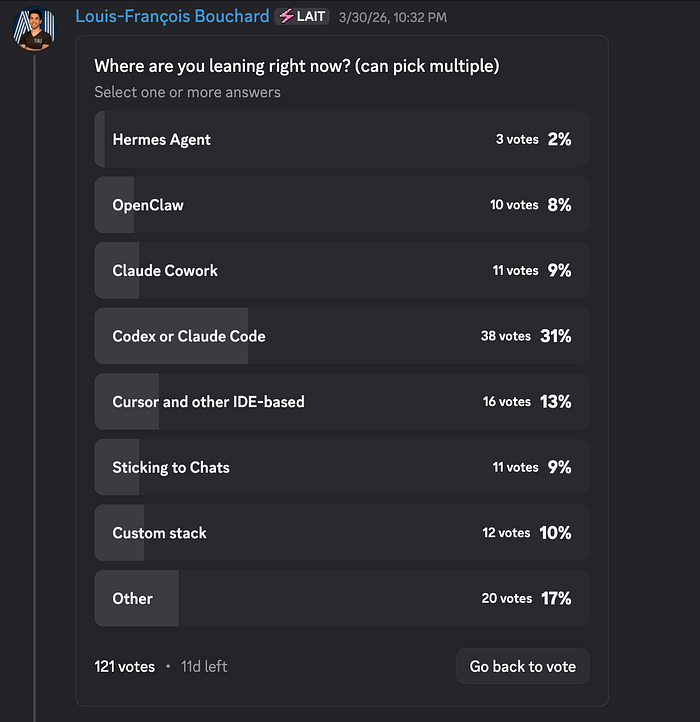
LAI #121: The single-agent sweet spot nobody wants to admit
Author(s): Towards AI Editorial Team Originally published on Towards AI. Good morning, AI enthusiasts! Your next AI system is probably too complicated, and you haven’t even built it yet. This week, we co-published a piece with Paul Iusztin that gives you a mental model for catching overengineering before it starts. Here’s what’s inside: Agent or workflow? Getting it wrong is where most production headaches begin. Do biases amplify as agents get more autonomous? What actually changes and how to control it at the system level. Claude Code’s three most ignored slash commands: /btw, /fork, and /rewind, and why they matter more the longer your session runs. The community voted on where coding agents are headed. Terminal-based tools are pulling ahead, but that 17% “Other” bucket is hiding someth
J-CHAT: Japanese Large-scale Spoken Dialogue Corpus for Spoken Dialogue Language Modeling
arXiv:2407.15828v2 Announce Type: replace-cross Abstract: Spoken dialogue is essential for human-AI interactions, providing expressive capabilities beyond text. Developing effective spoken dialogue systems (SDSs) requires large-scale, high-quality, and diverse spoken dialogue corpora. However, existing datasets are often limited in size, spontaneity, or linguistic coherence. To address these limitations, we introduce J-CHAT, a 76,000-hour open-source Japanese spoken dialogue corpus. Constructed using an automated, language-independent methodology, J-CHAT ensures acoustic cleanliness, diversity, and natural spontaneity. The corpus is built from YouTube and podcast data, with extensive filtering and denoising to enhance quality. Experimental results with generative spoken dialogue language m

Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Open Source AI


v4.3.1
Changes Gemma 4 support with full tool-calling in the API and UI. 🆕 ik_llama.cpp support : Add ik_llama.cpp as a new backend through new textgen-portable-ik portable builds and a new --ik flag for full installs. ik_llama.cpp is a fork by the author of the imatrix quants, including support for new quant types, significantly more accurate KV cache quantization (via Hadamard KV cache rotation, enabled by default), and optimizations for MoE models and CPU inference. API: Add echo + logprobs for /v1/completions . The completions endpoint now supports the echo and logprobs parameters, returning token-level log probabilities for both prompt and generated tokens. Token IDs are also included in the output via a new top_logprobs_ids field. Further optimize my custom gradio fork, saving up to 50 ms

From SWE-ZERO to SWE-HERO: Execution-free to Execution-based Fine-tuning for Software Engineering Agents
arXiv:2604.01496v1 Announce Type: new Abstract: We introduce SWE-ZERO to SWE-HERO, a two-stage SFT recipe that achieves state-of-the-art results on SWE-bench by distilling open-weight frontier LLMs. Our pipeline replaces resource-heavy dependencies with an evolutionary refinement strategy: (1) SWE-ZERO utilizes large-scale, execution-free trajectories to master code semantics and repository-level reasoning, and (2) SWE-HERO applies targeted, execution-backed refinement to transition these semantic intuitions into rigorous engineering workflows. Our empirical results set a new benchmark for open-source models of comparable size. We release a dataset of 300k SWE-ZERO and 13k SWE-HERO trajectories distilled from Qwen3-Coder-480B, alongside a suite of agents based on the Qwen2.5-Coder series.

A Quick Note on Gemma 4 Image Settings in Llama.cpp
In my last post, I mentioned using --image-min-tokens to increase the quality of image responses from Qwen3.5 . I went to load Gemma 4 the same way, and hit an error: [58175] srv process_chun: processing image... [58175] encoding image slice... [58175] image slice encoded in 7490 ms [58175] decoding image batch 1/2, n_tokens_batch = 2048 [58175] /Users/socg/llama.cpp-b8639/src/llama-context.cpp:1597: GGML_ASSERT((cparams.causal_attn || cparams.n_ubatch > = n_tokens_all ) "non-causal attention requires n_ubatch >= n_tokens" ) failed [58175] WARNING: Using native backtrace. Set GGML_BACKTRACE_LLDB for more info. [58175] WARNING: GGML_BACKTRACE_LLDB may cause native MacOS Terminal.app to crash. [58175] See: https://github.com/ggml-org/llama.cpp/pull/17869 [58175] 0 libggml-base.0.9.11.dylib 0
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!