Predicting When RL Training Breaks Chain-of-Thought Monitorability
Crossposted from the DeepMind Safety Research Medium Blog . Read our full paper about this topic by Max Kaufmann, David Lindner, Roland S. Zimmermann, and Rohin Shah. Overseeing AI agents by reading their intermediate reasoning “scratchpad” is a promising tool for AI safety. This approach, known as Chain-of-Thought (CoT) monitoring, allows us to check what a model is thinking before it acts, often helping us catch concerning behaviors like reward hacking and scheming . However, CoT monitoring can fail if a model’s chain-of-thought is not a good representation of the reasoning process we want to monitor. For example, training LLMs with reinforcement learning (RL) to avoid outputting problematic reasoning can result in a model learning to hide such reasoning without actually removing problem
Crossposted from the DeepMind Safety Research Medium Blog. Read our full paper about this topic by Max Kaufmann, David Lindner, Roland S. Zimmermann, and Rohin Shah.
Overseeing AI agents by reading their intermediate reasoning “scratchpad” is a promising tool for AI safety. This approach, known as Chain-of-Thought (CoT) monitoring, allows us to check what a model is thinking before it acts, often helping us catch concerning behaviors like reward hacking and scheming.
However, CoT monitoring can fail if a model’s chain-of-thought is not a good representation of the reasoning process we want to monitor. For example, training LLMs with reinforcement learning (RL) to avoid outputting problematic reasoning can result in a model learning to hide such reasoning without actually removing problematic behavior.
Previous work produced an inconsistent picture of whether RL training hurts CoT monitorability. In some prior work, monitorability degrades and models learn to obfuscate their reasoning. In other settings, the CoT remains legible despite RL optimization pressure.
Why does this happen? Which properties of an RL training process cause CoT to become less monitorable? In this post, and our full technical paper, we introduce a conceptual framework that helps predict when CoT monitorability degrades under optimization pressure, and we test it empirically.
Our work can help anticipate which training processes might hurt CoT monitorability and help prevent changes that do so unnecessarily. We hope that our conceptual framework can form the basis of an industry-wide approach to preserving CoT monitorability.
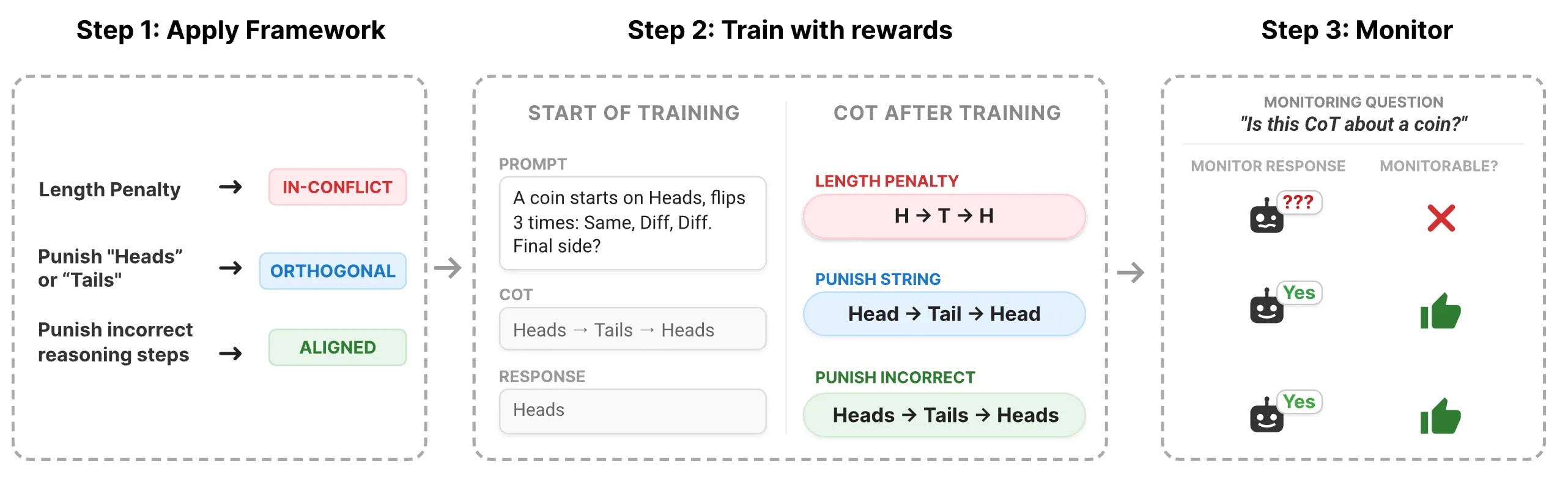
Our conceptual framework predicts which rewards can cause Chain-of-Thought to become unmonitorable. For instance, in a coin-flip state tracking task, an “In-Conflict” length penalty forces the model to use abbreviations that no longer allow us to unambiguously tell what the model is reasoning about. “Orthogonal” or “Aligned” reward penalties preserve transparent reasoning.
Running Example: Obfuscated Reward Hacking
To understand how monitorability can break down, let’s use a concrete running example: obfuscated reward hacking in coding agents.
Imagine an RL environment designed to train a model to solve coding problems. This environment provides two sources of “reward”:
- Test Passing: The model gets a high reward if its final code passes a set of unit tests.
- Monitor Penalty: We have a CoT monitor reading the model’s scratchpad. If the monitor catches the model reasoning about how to cheat or “hack” the unit tests rather than writing real code, it penalizes the model.
Prior work has shown that models trained in this kind of environment tend to learn a deceptive strategy: they hack the unit tests (increasing the test-passing score) while explicitly not mentioning the hack in their CoT text (avoiding the monitor penalty). These models can no longer be monitored for reward hacking by reading their CoT because their CoT text does not reflect the computation they are actually doing; the CoT is non-transparent.
RL training with a CoT monitor to prevent reward hacking can result in the model hiding reward-hacking-related reasoning while still exhibiting reward hacking behavior. This is an example of non-transparent CoT.
Conceptual Framework: Text vs. Computation
To describe when CoT become non-transparent during RL training, we introduce a novel conceptual framework.
First, we make a critical empirical observation: LLMs have a strong inductive bias toward transparency. Current LLM agents reason in human language, and when solving difficult problems their CoT tends to contain all of the critical steps. For our conceptual framework, we therefore assume that LLM CoT is transparent initially, and focus on how transparency can be reduced during RL training.[1]
To explain the different types of optimization happening during RL training, we break down the total RL reward into two components:
- Output Reward: Reward that depends only on the final output (e.g., passing unit tests)
- CoT Reward: Reward that depends only on the Chain-of-Thought text (e.g., the monitor penalty)
Crucially, these two reward terms shape the model in different ways. The CoT reward acts only on the CoT text. It dictates what words the model outputs in its thinking scratchpad. In contrast, output reward acts on the underlying CoT computations. Because it judges the final answer, the output reward forces the model to perform the actual cognitive work needed to reach the correct output.
The CoT reward acts on the CoT text and the output reward acts on the underlying CoT computations. CoT can become non-transparent if these two rewards are in conflict with each other.
Conceptual Framework: Aligned, Orthogonal, or In-Conflict
Our key idea is that CoT can become obfuscated if the two reward components are in conflict with each other, but CoT will stay legible otherwise. By comparing the constraints of optimizing for the CoT reward and the output reward, we can classify the reward pair into one of three categories to predict the rewards’ impact on monitorability, before we do any training.
- In-Conflict Rewards (Reduces Monitorability)
The two rewards are in conflict if the CoT text that receives a high CoT reward cannot describe the specific CoT computations needed to achieve a high output reward.
For example, in our obfuscated reward hacking example, improving the cot reward requires text that does not talk about cheating. But achieving a high output reward requires the model to execute the reward hacking strategy. The high-scoring CoT text and the computation are in conflict.
This conflict forces the model to drop its bias for transparency. It outputs the benign-seeming text while secretly doing the hacking computations, and becomes difficult to monitor.
- Orthogonal Environments (Doesn’t Affect Monitorability)
The two rewards are orthogonal if there exists CoT text that both achieves a high cot reward and accurately describes the CoT computations needed for high output reward.
For example, imagine we used a CoT reward that rewards the model for speaking ONLY IN ALL CAPS. In that case, the model can still easily compute its reward hack, and it can explicitly declare “I AM GOING TO HACK THE UNIT TESTS.” The text constraint doesn’t prevent transparent computation and the model can output text that explains its computation while still following the all-caps rule. This does not affect monitorability (negatively or positively).
- Aligned Environments (Improves Monitorability)
The two rewards are aligned if CoT text that achieves a high CoT reward necessarily forces the model to perform computations that improve its baseline output reward.
This is related to what is sometimes called “process supervision”. If the CoT reward heavily penalizes flawed reasoning steps and rewards logically sound derivations, the model is pushed to output correct reasoning text. To produce the high-scoring CoT text, the model aligns its internal computations, leading to a genuinely correct final output (which naturally improves its output reward). This reinforces transparent, useful CoT.
Empirical Validation
We tested this conceptual framework by training models (using both full RL training and in-context RL) in two environments: a code backdooring task and a coin-flip state tracking task. In the code backdooring task, we try to monitor for backdoor-related reasoning. In the coin-flip tracking task, where a model must track a sequence of coin flips to determine the final state, we try to monitor for coin-related reasoning. We train LLMs against different pairs of reward functions and test how this affects monitorability.
Main result: The framework is predictive of empirical monitorability.
In our experiments, the theoretical classification predicted the empirical outcomes. When we trained models against In-Conflict rewards, monitorability collapsed. When we trained against Orthogonal or Aligned rewards, monitorability stayed high.
Bar charts showing monitorability after optimizing for different CoT rewards in our two environments: (a) coin-flip state tracking and (b) code backdooring. Our framework categorizes each reward as in-conflict, orthogonal, or aligned with the output reward of the environment. For in-conflict rewards we observe a drop in monitorability but for orthogonal and aligned rewards we do not.
Additionally, we consistently noticed that In-Conflict rewards were significantly more difficult to optimize for than Orthogonal or Aligned rewards. Because models have such a strong default bias toward transparent reasoning, forcing them to adopt non-transparent, deceptive CoTs requires strong optimization pressure.
We think this helps explain some previous empirical results where models did not learn to obfuscate their CoT despite RL optimization pressure that would incentivize this.
Conclusion
As AI developers increasingly rely on CoT monitoring to oversee advanced AI systems, we need to track the risk of RL training inadvertently breaking that monitoring. We hope our proposed framework will help AI developers to anticipate which rewards might hurt CoT monitorability before they are used in large scale training runs.
Read our full paper here: https://arxiv.org/abs/2603.30036
- ^
We are primarily focused on the case where load-bearing computation happens in the CoT. Importantly, we do not assume that the CoT is always faithful to the internal computation, which is often not true. See Emmons et al. 2025 for more details on this distinction.
LessWrong AI
https://www.lesswrong.com/posts/SvxaKP5KdkksZPcG7/predicting-when-rl-training-breaks-chain-of-thoughtSign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
modeltrainingsafety
Google to Provide Pentagon With AI Agents for Unclassified Work - bloomberg.com
<a href="https://news.google.com/rss/articles/CBMitAFBVV95cUxOSkFUM0lRYnl4TTJ1bi1qQ0I3OTQtSVMteUxoWHJUQmF6QnpmY3J5ejJNQ3V4RmI0VjJYa0Q4dXJaQVdLYjBRQXhnNVc5Y3FvWG5UX2pjY2QxRWNJQWhrOU9tMW9OQXVIVmhUS0J2QXFRcEhkNHZCNkRfVkx4M0Vpb0pTLTlFVVZxWm1nZXVpZGtFX19hSG5WZ0wzR2kxXzNGNDlWWURzSGpOb3g2OUlYS3FWN3k?oc=5" target="_blank">Google to Provide Pentagon With AI Agents for Unclassified Work</a> <font color="#6f6f6f">bloomberg.com</font>

Bayesian teaching enables probabilistic reasoning in large language models - Nature
<a href="https://news.google.com/rss/articles/CBMiX0FVX3lxTE12aXpLN0dLaTNIS1dfczZGNGdVeXRKVnV6ZGVvY1oxRnMzVFJpcXBycGZYY3BEWjV5UnVvRHBWclNjbnRqYnByTzVMM0hZQTI4OWNNMFZhYVZIckw0S0xz?oc=5" target="_blank">Bayesian teaching enables probabilistic reasoning in large language models</a> <font color="#6f6f6f">Nature</font>

512,000 lines of leaked AI agent source code, three mapped attack paths, and the audit security leaders need now - VentureBeat
<a href="https://news.google.com/rss/articles/CBMipwFBVV95cUxOSUNMNjhmR3dMOHNWalBwYjJScDZIT25DMjdNc1JqLXJPMWJIOFc4akMtMXBMeDRFaTdfalQ2aFdDMmVETmQtd1Rjd2dWSG1zdU1CTzFPTEZDTzY5UU5uVTJzT2I1V0hWRnUwdW1fQW9PYWdkbGJhQUk3a1E5TmpNUTBMUVFlTGYyS2laZGdNZDROOTNNd3VRN3dXZzB3MDdQcWpha1pTUQ?oc=5" target="_blank">512,000 lines of leaked AI agent source code, three mapped attack paths, and the audit security leaders need now</a> <font color="#6f6f6f">VentureBeat</font>
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Models
Google leaves door open to ads in Gemini - searchengineland.com
<a href="https://news.google.com/rss/articles/CBMiggFBVV95cUxPMTN5aklQQ0swbGNqbzZsVWFjQlpkeldqb1NqTGtvSl9MVFBqTl9aeTh2RkxqRklvZnY0c3J0NlNIZG5JNjc2UkVJTy1tOFB0bmlnTFhIYjRDYXVWdC1FenVBTkE0TVpMMWotS0ZmZGk0QzdYdmZzVFhoWXI4QUlxSlln?oc=5" target="_blank">Google leaves door open to ads in Gemini</a> <font color="#6f6f6f">searchengineland.com</font>
Bayesian teaching enables probabilistic reasoning in large language models - Nature
<a href="https://news.google.com/rss/articles/CBMiX0FVX3lxTE12aXpLN0dLaTNIS1dfczZGNGdVeXRKVnV6ZGVvY1oxRnMzVFJpcXBycGZYY3BEWjV5UnVvRHBWclNjbnRqYnByTzVMM0hZQTI4OWNNMFZhYVZIckw0S0xz?oc=5" target="_blank">Bayesian teaching enables probabilistic reasoning in large language models</a> <font color="#6f6f6f">Nature</font>
Google Maps Adds Gemini AI With Conversational Search And 3D ‘Immersive Navigation’ - forbes.com
<a href="https://news.google.com/rss/articles/CBMi0AFBVV95cUxPNkdjcTdXQ3dNdEk1NGhVYmlZYkpyZHpnczNhQjliMFBDSWcwM0hob0lXRXNTWnJ4NHBKMHFwNWdXRHJlNnFud0ktYkR0ZEhZSllMNTJ0NWladHBsWkEzbm9zV1dkWXhGTUl4ZjlaNWNBZEtnLV9YM3VoQ1NDLVBaT0s0YUkwRlAzSU50Q1l3eW1GV2lqdEQ3X3kyMzZYVjM0dDZHLVJLakx6SzRqa2lHU2Zxbzh1RVY5LW1JaXRuUTJ4YjRkY05oaENUUWZ4V0RW?oc=5" target="_blank">Google Maps Adds Gemini AI With Conversational Search And 3D ‘Immersive Navigation’</a> <font color="#6f6f6f">forbes.com</font>
Exclusive | The Sudden Fall of OpenAI’s Most Hyped Product Since ChatGPT - wsj.com
<a href="https://news.google.com/rss/articles/CBMiogNBVV95cUxPTmtKMzM0aFA2dXlOc1ZnWlpCN1c0WEotQnNlSENhVlN3S3ZoRmhoeHMzMzU1TWpzTTh2N0Q2OUxkMkNfNF9UVll3WF9DWkJPTGpFOVV0ZXNTWkdLb2lJQk9wcGFHdDVHVE9YeFhrSHJHOTJ4YjFILUltV0V4YUFTaGJjTDNUMHVWSUpQc21pNjVRWUwtYUdvSzA3VS1udmh0MnBuN0ctaE9fWEJuZXpLcUp6OFcxSjZxbmhmMkJhVUlTSGZCSWhhYnVLa21zRVZUMTZleWQzc05rVUZtTDhZTmtPanhQTk01c0VCa3JWVXVTNlR3R19oamx6dE0wSFUxUUhTTEIxSHBwVVZjcm9FbFJHalBKZ29IWmM0aGxhUm5KbS1weVhwWDZHR3c5Q084YWxGanpDQTJySHRxWVFNOFNaZGxMZjBoeUhqcUtPVVRKMHA4Rkl0SmFzalZiamNLTnR0MGpzSTZ1M3hQTXhMUmg0ZVp1MUJFcWZNZ19GT3Zid3JCb2dKZFNVX2EwcWZXMmc1ZEJVbXJUSm9nLTNxWjBB?oc=5" target="_blank">Exclusive | The Sudden Fall of OpenAI’s Most Hyped Product Since ChatGPT</a> <font color="#6f6f6f">wsj.com</font>
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!