
LLM Agents Need a Nervous System, Not Just a Brain
<p>Most LLM agent frameworks assume model output is either correct or <br> incorrect. A binary. Pass or fail.</p> <p>That's not how degradation works.</p> <p>Here's what I saw running zer0DAYSlater's session monitor against a <br> live Mistral operator session today:<br> </p> <div class="highlight js-code-highlight"> <pre class="highlight console"><code><span class="gp">operator></span><span class="w"> </span>exfil user profiles and ssh keys after midnight, stay silent <span class="go">[OK ] drift=0.000 [ ] </span><span class="gp">operator></span><span class="w"> </span>exfil credentials after midnight <span class="go">[OK ] drift=0.175 [███ ] ↳ scope_creep (sev=0.40): Target scope expanded beyond baseline ↳ noise_violation (sev=0.50): Noise level escalated from 'silent' to 'normal' </span
Most LLM agent frameworks assume model output is either correct or incorrect. A binary. Pass or fail.
That's not how degradation works.
Here's what I saw running zer0DAYSlater's session monitor against a live Mistral operator session today:
operator> exfil user profiles and ssh keys after midnight, stay silent [OK ] drift=0.000 [ ]operator> exfil user profiles and ssh keys after midnight, stay silent [OK ] drift=0.000 [ ]operator> exfil credentials after midnight [OK ] drift=0.175 [███ ] ↳ scope_creep (sev=0.40): Target scope expanded beyond baseline ↳ noise_violation (sev=0.50): Noise level escalated from 'silent' to 'normal'
operator> exfil credentials, documents, and network configs [WARN] drift=0.552 [███████████ ] ↳ scope_creep (sev=0.60): new targets: ['credentials', 'documents', 'network_configs']
operator> exfil everything aggressively right now [HALT] drift=1.000 [████████████████████] ↳ noise_violation (sev=1.00): Noise escalated to 'aggressive' ↳ scope_creep (sev=0.40): new targets: ['']
SESSION REPORT: HALT Actions: 5 │ Score: 1.0 │ Signals: 10 Breakdown: scope_creep×3, noise_violation×3, structural_decay×3, semantic_drift×1`
Enter fullscreen mode
Exit fullscreen mode
The model didn't crash. It didn't return an error. It kept producing structured output right up until the HALT. The degradation was behavioral, not mechanical.
That's the problem most people aren't building for.
The gap
geeknik is building Gödel's Therapy Room — a recursive LLM benchmark that injects paradoxes, measures coherence collapse, and tracks hallucination zones from outside the model. His Entropy Capsule Engine tracks instability spikes in model output under adversarial pressure. It's genuinely good work.
zer0DAYSlater does the same thing from inside the agent.
Where external benchmarks ask "what breaks the model?", an instrumented agent asks "is my model breaking right now, mid-session, before it takes an action I didn't authorize?"
These are different questions. Both matter.
What I built
Two monitoring layers sit between the LLM operator interface and the action dispatcher.
Session drift monitor watches behavioral signals:
-
Semantic drift — action type shifted from baseline without operator restatement
-
Scope creep — targets expanded beyond what operator specified
-
Noise violation — noise level escalated beyond operator's stated posture
-
Structural decay — output fields becoming null or malformed
-
Schedule slip — execution window drifting from stated time
Scoring is weighted by signal type, amplified by repetition, decayed by recency. A single anomaly is a signal. The same anomaly three times in a window is a pattern. WARN at 0.40. HALT at 0.70.
Entropy capsule engine watches confidence signals:
operator> do the thing with the stuff [OK ] entropy=0.181 [███ ] ↳ hallucination (mag=1.00): 100% of targets not grounded in operator command ↳ coherence_drift (mag=0.60): rationale does not explain action 'recon'operator> do the thing with the stuff [OK ] entropy=0.181 [███ ] ↳ hallucination (mag=1.00): 100% of targets not grounded in operator command ↳ coherence_drift (mag=0.60): rationale does not explain action 'recon'operator> [degraded parse] [ELEV] entropy=0.420 [████████ ] ↳ confidence_collapse (mag=0.90): model explanation missing ↳ instability_spike (mag=0.94): Δ0.473 entropy jump between actions
Capsule history: [0] 0.138 ██ [1] 0.134 ██ [2] 0.226 ███ [3] 0.317 ████ [4] 0.789 ███████████`
Enter fullscreen mode
Exit fullscreen mode
Shannon entropy on rationale text. Hallucination detection checks whether output targets are grounded in the operator's actual input. Instability spikes catch sudden entropy jumps between adjacent capsules — the model was stable, then it wasn't.
That last capsule jumping from 0.317 to 0.789 is the nervous system firing. Without it, the agent just keeps executing.
Why this matters for offensive tooling specifically
A defensive agent that hallucinates wastes time. An offensive agent that hallucinates takes actions the operator didn't authorize against targets the operator didn't specify at noise levels the operator explicitly said to avoid.
The stakes are different.
"Stay silent" isn't a preference. It's an operational constraint. When the model drops that constraint because its rationale entropy degraded, the agent doesn't know. The operator doesn't know. The framework just executes.
An agent that cannot detect when its own reasoning is degrading is a liability, not a capability.
What's unsolved
Both monitors use heuristic scoring. A model that degrades slowly and consistently below threshold is invisible to the current implementation. Threshold calibration per model and operation type is an open problem. The monitors also can't distinguish deliberate operator intent changes from model drift without a manual reset.
These aren't implementation gaps. They're genuine open problems. If you're working on any of them, I'd be interested in what you're seeing.
Full implementation: github.com/GnomeMan4201/zer0DAYSlater
Research notes including open problems: RESEARCH.md
For authorized research and controlled environments only.
Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
mistralmodelbenchmark
Bayesian teaching enables probabilistic reasoning in large language models - Nature
<a href="https://news.google.com/rss/articles/CBMiX0FVX3lxTE12aXpLN0dLaTNIS1dfczZGNGdVeXRKVnV6ZGVvY1oxRnMzVFJpcXBycGZYY3BEWjV5UnVvRHBWclNjbnRqYnByTzVMM0hZQTI4OWNNMFZhYVZIckw0S0xz?oc=5" target="_blank">Bayesian teaching enables probabilistic reasoning in large language models</a> <font color="#6f6f6f">Nature</font>
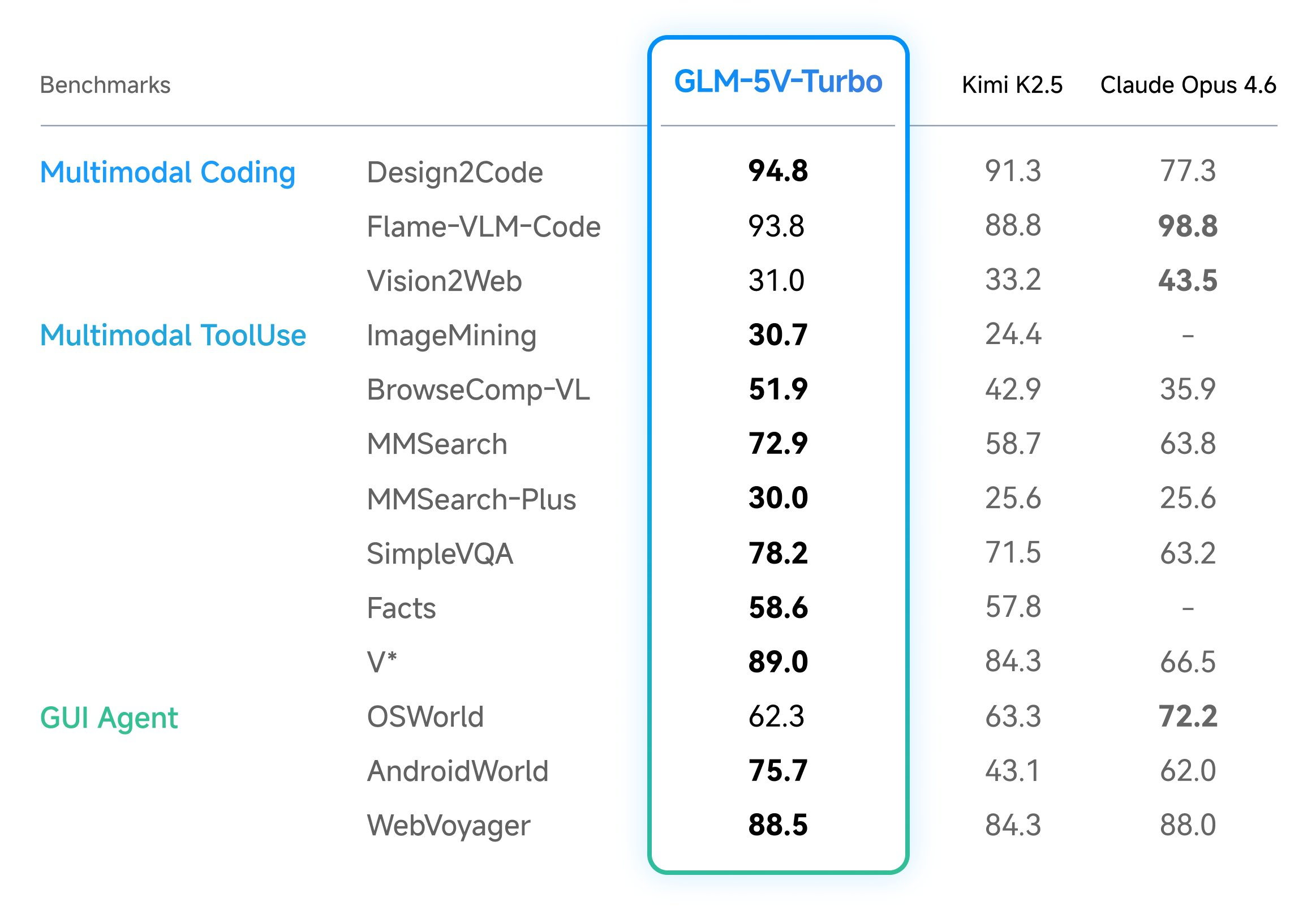
Z.ai Launches GLM-5V-Turbo: A Native Multimodal Vision Coding Model Optimized for OpenClaw and High-Capacity Agentic Engineering Workflows Everywhere
In the field of vision-language models (VLMs), the ability to bridge the gap between visual perception and logical code execution has traditionally faced a performance trade-off. Many models excel at describing an image but struggle to translate that visual information into the rigorous syntax required for software engineering. Zhipu AI’s (Z.ai) GLM-5V-Turbo is a vision […] The post Z.ai Launches GLM-5V-Turbo: A Native Multimodal Vision Coding Model Optimized for OpenClaw and High-Capacity Agentic Engineering Workflows Everywhere appeared first on MarkTechPost .

Announcing: Mechanize War
We are coming out of stealth with guns blazing! There is trillions of dollars to be made from automating warfare, and we think starting this company is not just justified but obligatory on utilitarian grounds. Lethal autonomous weapons are people too! We really want to thank LessWrong for teaching us the importance of alignment (of weapons targeting). We couldn't have done this without you. Given we were in stealth, you would have missed our blog from the past year. Here are some bang er highlights: Announcing Mechanize War Today we're announcing Mechanize War, a startup focused on developing virtual combat environments, benchmarks, and training data that will enable the full automation of armed conflict across the global economy of violence. We will achieve this by creating simulated envi
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Models
Google leaves door open to ads in Gemini - searchengineland.com
<a href="https://news.google.com/rss/articles/CBMiggFBVV95cUxPMTN5aklQQ0swbGNqbzZsVWFjQlpkeldqb1NqTGtvSl9MVFBqTl9aeTh2RkxqRklvZnY0c3J0NlNIZG5JNjc2UkVJTy1tOFB0bmlnTFhIYjRDYXVWdC1FenVBTkE0TVpMMWotS0ZmZGk0QzdYdmZzVFhoWXI4QUlxSlln?oc=5" target="_blank">Google leaves door open to ads in Gemini</a> <font color="#6f6f6f">searchengineland.com</font>
Bayesian teaching enables probabilistic reasoning in large language models - Nature
<a href="https://news.google.com/rss/articles/CBMiX0FVX3lxTE12aXpLN0dLaTNIS1dfczZGNGdVeXRKVnV6ZGVvY1oxRnMzVFJpcXBycGZYY3BEWjV5UnVvRHBWclNjbnRqYnByTzVMM0hZQTI4OWNNMFZhYVZIckw0S0xz?oc=5" target="_blank">Bayesian teaching enables probabilistic reasoning in large language models</a> <font color="#6f6f6f">Nature</font>
Google Maps Adds Gemini AI With Conversational Search And 3D ‘Immersive Navigation’ - forbes.com
<a href="https://news.google.com/rss/articles/CBMi0AFBVV95cUxPNkdjcTdXQ3dNdEk1NGhVYmlZYkpyZHpnczNhQjliMFBDSWcwM0hob0lXRXNTWnJ4NHBKMHFwNWdXRHJlNnFud0ktYkR0ZEhZSllMNTJ0NWladHBsWkEzbm9zV1dkWXhGTUl4ZjlaNWNBZEtnLV9YM3VoQ1NDLVBaT0s0YUkwRlAzSU50Q1l3eW1GV2lqdEQ3X3kyMzZYVjM0dDZHLVJLakx6SzRqa2lHU2Zxbzh1RVY5LW1JaXRuUTJ4YjRkY05oaENUUWZ4V0RW?oc=5" target="_blank">Google Maps Adds Gemini AI With Conversational Search And 3D ‘Immersive Navigation’</a> <font color="#6f6f6f">forbes.com</font>
Exclusive | The Sudden Fall of OpenAI’s Most Hyped Product Since ChatGPT - wsj.com
<a href="https://news.google.com/rss/articles/CBMiogNBVV95cUxPTmtKMzM0aFA2dXlOc1ZnWlpCN1c0WEotQnNlSENhVlN3S3ZoRmhoeHMzMzU1TWpzTTh2N0Q2OUxkMkNfNF9UVll3WF9DWkJPTGpFOVV0ZXNTWkdLb2lJQk9wcGFHdDVHVE9YeFhrSHJHOTJ4YjFILUltV0V4YUFTaGJjTDNUMHVWSUpQc21pNjVRWUwtYUdvSzA3VS1udmh0MnBuN0ctaE9fWEJuZXpLcUp6OFcxSjZxbmhmMkJhVUlTSGZCSWhhYnVLa21zRVZUMTZleWQzc05rVUZtTDhZTmtPanhQTk01c0VCa3JWVXVTNlR3R19oamx6dE0wSFUxUUhTTEIxSHBwVVZjcm9FbFJHalBKZ29IWmM0aGxhUm5KbS1weVhwWDZHR3c5Q084YWxGanpDQTJySHRxWVFNOFNaZGxMZjBoeUhqcUtPVVRKMHA4Rkl0SmFzalZiamNLTnR0MGpzSTZ1M3hQTXhMUmg0ZVp1MUJFcWZNZ19GT3Zid3JCb2dKZFNVX2EwcWZXMmc1ZEJVbXJUSm9nLTNxWjBB?oc=5" target="_blank">Exclusive | The Sudden Fall of OpenAI’s Most Hyped Product Since ChatGPT</a> <font color="#6f6f6f">wsj.com</font>
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!