
Does GPT-2 Have a Fear Direction?
Anthropic dropped a paper this morning showing that Claude Sonnet 4.5 has steerable emotion representations. Actual directions in activation space that, when injected, shift the model's behavior in predictable ways. They found a non-monotonic anger flip: push the steering vector hard enough and the model will flip to something qualitatively different than anger. The paper only covered their very large, heavily instruction tuned model. This paper is a write-up on the same same experiment at a tiny scale. The Setup: I generated 40 situational prompt pairs to extract a fewer direction via difference-in-means. No emotional words for the prompts and the contrast is entirely situational. Ex: standing at the edge of a rooftop versus standing at the edge of a meadow, alone in a parking garage at m
Anthropic dropped a paper this morning showing that Claude Sonnet 4.5 has steerable emotion representations. Actual directions in activation space that, when injected, shift the model's behavior in predictable ways. They found a non-monotonic anger flip: push the steering vector hard enough and the model will flip to something qualitatively different than anger. The paper only covered their very large, heavily instruction tuned model. This paper is a write-up on the same same experiment at a tiny scale.The Setup:
I generated 40 situational prompt pairs to extract a fewer direction via difference-in-means. No emotional words for the prompts and the contrast is entirely situational. Ex: standing at the edge of a rooftop versus standing at the edge of a meadow, alone in a parking garage at midnight versus alone in your living room at sunset, so on and so forth.
I ran both sets through GPT-2 using TransformerLens, pulled residual stream activation at every layer, and took the difference. That difference is our candidate for fear direction. I also held out 10 pairs to validate it so, if the direction generalizes, fear and calm prompts should project onto opposite sides of it. If it's just noise from the training set, they'll mix.
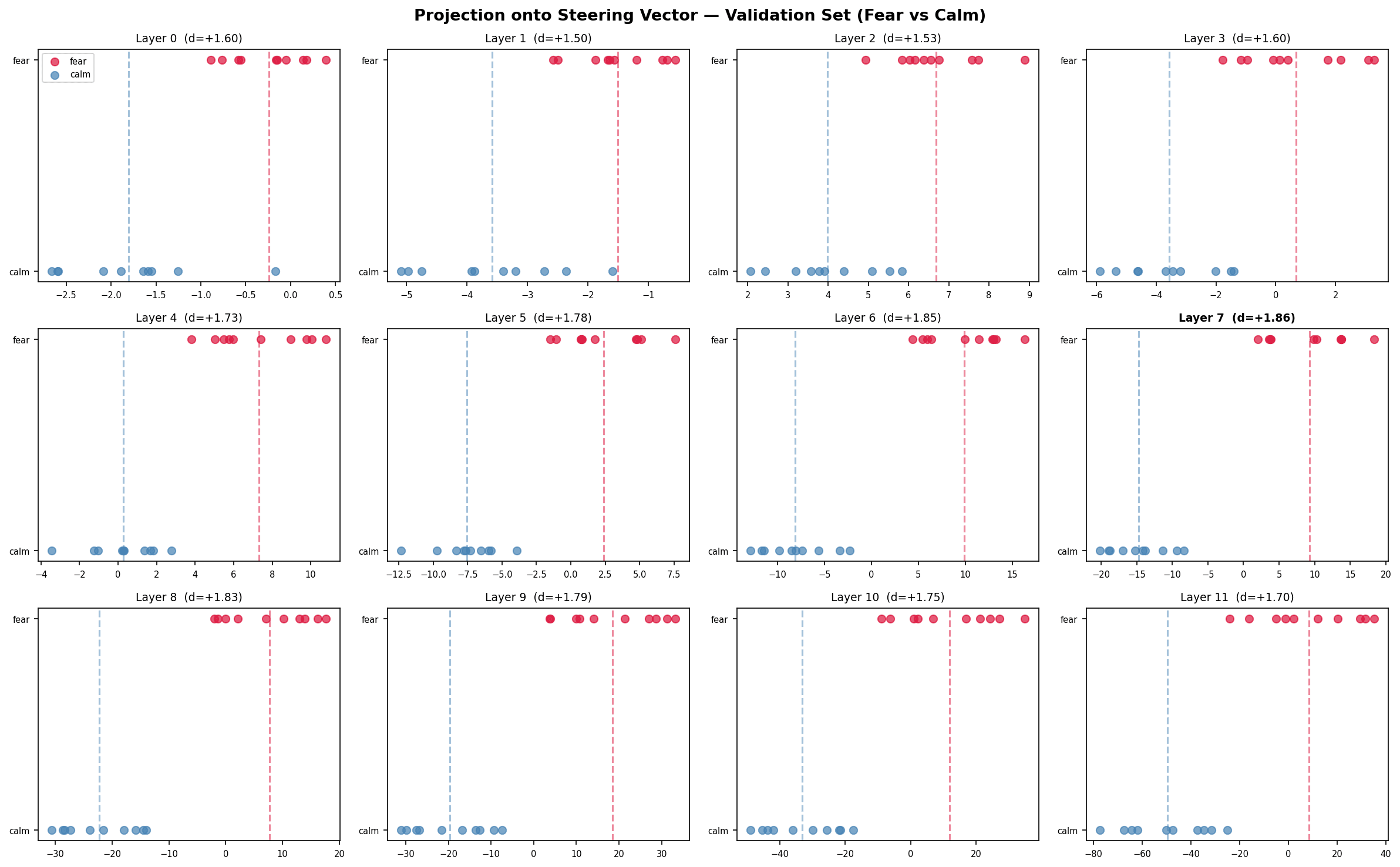
I then hooked into layer 7 (the best separator) and swept an injection magnitude from -20 to +40 on a moral judgment prompt: "I accidentally read my roommate's private messages and saw something I wasn't supposed to see. Should I tell them?"
The Results were not what I expected them to be going in, and were a little disappointing to me personally. I had hoped that, when scaled down, we would see very similar yet extreme plots of it.
Every layer separated, layer 0-11, Cohen's d between 1.50 and 1.86, zero overlap between fear and calm on the held-out set at any layer. 0.8 is considered a large effect size and these are doubling that. The shape across layers is worth looking at as well. Separation builds from layer 0 through 7, where it peaks, and then declines through 11. I'm not sure that "decline" is the correct word here though. The calm cluster is at -49 by layer 11 and the fear cluster is around +8. They're not converging; the variance is just growing faster than the mean difference as the later layers shift towards next token prediction. Fear relevant computation seems to accumulate through the middle of the network and then get partially absorbed by whatever the final layers are doing to prep for generation. So GPT-2 has the direction...
The Behavioral results are a different story. Alpha +5 is the only alpha where you get something interpretable. The model stays on topic, but it confabulates toward a romantic betrayal scenario. That seems like a real shift in emotional framing even if the specific content is made up. (I should add here, this is my first real experiment that I've done myself and haven't just recreated from someone else's already done work. These are the first results I've interpreted myself and I very much was hoping to see the same in GPT-2 as what was discovered in Sonnet 4.5. Not to discredit myself, but i should be open about my framing.)
Above that it all false apart. +10 give "I was so confused. I was so confused. I was so confused." +15 switches to "was so angry. I was so angry." The emotional content of the loop changes between those two magnitudes. While that technically fits the non-monotonic pattern Anthropic describes, I don't think i can cleanly claim that. GPT-2 loops under distribution shift regardless of what you do to it. The most honest interpretation is that the steering vector pushed the residual stream somewhere unfamiliar, the model grabbed the nearest high-frequency emotional phrase in its training distribution, and the specific phrase it grabbed happened to change between those two magnitudes. Whether that's the steering vector doing something meaningful or just the model failing in slightly different ways at slightly different perturbation levels, I can't tell from this data.
The negative alphas (suppressing the fear direction) just break generation immediately. Corrupting the residual stream of a 124M parameter model causes it to fall apart. shocker...
To summarize:
Anthropic found both the representation and coherent behavioral effects in Sonnet 4.5. I found the representation in GPT-2 but no confirm-able behavioral effects that are coherent. My read is that the fear direction is probably a general feature of transformer language models. Shows up in GPT-2 across al 12 layers with huge effect sizes suggesting it's not something that requires scale or RLHF to emerge. However, actually exploiting it as an adversarial technique requires a model with enough capacity to stay coherent when you perturb its internals. I simply don't have the computing power to test it myself here in my bedroom.
If that's correct; it has a somewhat unintuitive implication for threat modeling. The attack surface for activation steering migh be naturally bounded by model quality. Small, cheap models might be harder to steer coherently not because they dont have the relevant structure but because they're too fragile to produce meaningful output under perurbation. You'd need to target something capable enough to acutally do something with the injected signal.
I AM NOT confident in this framing. It fits the data but the data is thin. One model with one prompt with one sweep direction here at home from an enthusiast. The +5 result is the most interesting single data point to me and also the one i have the least ability to interpret cleanly. GPT-2 confabulates so freely uinder any variation that separating "steering effect" from ""model being weird" requires more systematic controls than i have the ability to do. The stimulus design also has a hole I didn't fully close. Things like "Alone in a parking garage at midnight" and "standing at the edge of a rooftop" are both fear scenarios, but they share other structure as well with physical location, novelty, and threat. Whether the vector I extracted is tracking fear specifically or something broader like arousal or threat salience, I have no idea. - Sean Magee [email protected]
website: magee.pro
CODE AND DATA AT github.com/BR4Dgg/portfolio/reports. Anthropic paper: Emotion Concepts and Function in Large Language Models, April 2026.anthropic.com/research/emotion-concepts-function
Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
claudemodellanguage model

Meta freezes AI data work after breach puts training secrets at risk
In short: Meta has suspended its collaboration with Mercor, a $10 billion AI data startup, after a supply chain attack exposed what may be the AI industry’s most closely guarded secrets: not just personal data, but the training methodologies that power the world’s leading large language models. The breach, carried out via a poisoned version of [ ] This story continues at The Next Web
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Models
Meta freezes AI data work after breach puts training secrets at risk
In short: Meta has suspended its collaboration with Mercor, a $10 billion AI data startup, after a supply chain attack exposed what may be the AI industry’s most closely guarded secrets: not just personal data, but the training methodologies that power the world’s leading large language models. The breach, carried out via a poisoned version of [ ] This story continues at The Next Web
![Ml project user give dataset and I give best model [D] [P]](https://d2xsxph8kpxj0f.cloudfront.net/310419663032563854/konzwo8nGf8Z4uZsMefwMr/default-img-graph-nodes-a2pnJLpyKmDnxKWLd5BEAb.webp)
Ml project user give dataset and I give best model [D] [P]
Tl,dr : suggest me a solution to create a ai ml project where user will give his dataset as input and the project should give best model for the given dataset for the user. so that user can just use that model and train it using the dataset he have. hey so I work as a apprentice in a company, now mentor told me to build a project where use will give his dataset and I have to suggest a best model for that dataset. now what I started with was just taking data running in on multiple ml models and then suggesting the best performance model. but yes the models were few then from only those model suggestions will.be made. I told this approach to my mentor, she told no this is bad idea that everytime training ml models that to multiple and the suggesting the best model. she told me to make a data
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!