
Deep Dive: Array Internals & Memory Layout
<h2> Array Internals & Memory Layout </h2> <p><strong>WHAT YOU'LL LEARN</strong></p> <ul> <li>Arrays store elements in contiguous memory blocks — each element sits right next to the previous one</li> <li>Random access is O(1) because the address of arr[i] is just baseAddress + i * elementSize — a single arithmetic operation</li> <li>Insertion/deletion at arbitrary positions is O(n) because elements must be shifted to maintain contiguity</li> <li>JavaScript arrays are actually hash maps under the hood for sparse arrays, but V8 optimizes dense arrays to use contiguous backing stores</li> </ul> <blockquote> <p><strong>Why it matters:</strong> Understanding the memory model explains WHY array operations have the complexities they do, rather than memorizing a table. It also informs when to
Array Internals & Memory Layout
WHAT YOU'LL LEARN
-
Arrays store elements in contiguous memory blocks — each element sits right next to the previous one
-
Random access is O(1) because the address of arr[i] is just baseAddress + i * elementSize — a single arithmetic operation
-
Insertion/deletion at arbitrary positions is O(n) because elements must be shifted to maintain contiguity
-
JavaScript arrays are actually hash maps under the hood for sparse arrays, but V8 optimizes dense arrays to use contiguous backing stores*
Why it matters: Understanding the memory model explains WHY array operations have the complexities they do, rather than memorizing a table. It also informs when to choose arrays vs. linked lists or hash maps.
Contiguous Memory & O(1) Access
In a true array, elements are packed sequentially in memory. To read arr[i], the CPU computes baseAddress + i * sizeof(element) and jumps directly there — no traversal needed. This is why arrays have O(1) random access while linked lists have O(n). In JavaScript, V8 uses 'SMI' (Small Integer) arrays and 'PACKED_DOUBLE' arrays that behave like true contiguous arrays for performance.*
// O(1) — direct index access const arr = [10, 20, 30, 40, 50]; console.log(arr[3]); // 40 — computed in constant time// O(1) — direct index access const arr = [10, 20, 30, 40, 50]; console.log(arr[3]); // 40 — computed in constant time// O(n) — insertion shifts all elements after index arr.splice(1, 0, 15); // Insert 15 at index 1 // [10, 15, 20, 30, 40, 50] // Elements 20, 30, 40, 50 all shifted right
// O(1) — push to end (amortized) arr.push(60); // No shifting, just append
// O(n) — unshift to front arr.unshift(5); // All elements shift right`
Enter fullscreen mode
Exit fullscreen mode
Cache Locality & Performance
Contiguous memory means arrays are cache-friendly. When the CPU loads arr[0], the cache line typically pulls in arr[1] through arr[7] as well. Sequential iteration exploits this prefetching, making arrays dramatically faster than linked lists for traversal even though both are O(n). This is why algorithms that iterate arrays sequentially (like prefix sum) perform better in practice than their Big-O alone suggests.
// Cache-friendly: sequential access pattern function sum(arr) { let total = 0; for (let i = 0; i < arr.length; i++) { total += arr[i]; // Next element is already in CPU cache } return total; }// Cache-friendly: sequential access pattern function sum(arr) { let total = 0; for (let i = 0; i < arr.length; i++) { total += arr[i]; // Next element is already in CPU cache } return total; }// Cache-unfriendly: random access pattern function randomSum(arr, indices) { let total = 0; for (const i of indices) { total += arr[i]; // Likely cache miss each time } return total; }`
Enter fullscreen mode
Exit fullscreen mode
Dynamic Array Resizing (Amortized O(1) Push)
JavaScript arrays (and C++ vectors, Java ArrayLists) use dynamic resizing. When the backing store is full, a new array of 2x size is allocated and elements are copied over. The copy is O(n), but it happens exponentially less often. Amortized over n pushes, each push costs O(1). This is why push() is O(1) amortized but splice(0, 0, x) is always O(n).
// Simulating dynamic array resizing class DynamicArray { constructor() { this.data = new Array(4); // initial capacity this.size = 0; this.capacity = 4; }// Simulating dynamic array resizing class DynamicArray { constructor() { this.data = new Array(4); // initial capacity this.size = 0; this.capacity = 4; }push(val) { if (this.size === this.capacity) { this.capacity = 2; // double capacity const newData = new Array(this.capacity); for (let i = 0; i < this.size; i++) { newData[i] = this.data[i]; // O(n) copy — rare } this.data = newData; } this.data[this.size] = val; // O(1) this.size++; }
get(i) { return this.data[i]; // O(1) random access } }`
Enter fullscreen mode
Exit fullscreen mode
Choosing the right data structure based on access pattern
Tricky Parts
JavaScript arrays aren't always contiguous
If you create a sparse array like const a = []; a[1000] = 1;, V8 switches to dictionary mode (hash map). Dense arrays with sequential indices get the fast contiguous path. Avoid holes to keep arrays optimized.
splice() vs pop() — big performance difference
arr.splice(0, 1) is O(n) because every element shifts. arr.pop() is O(1). For queue behavior (FIFO), don't use shift() on large arrays — use a proper queue or circular buffer.
Amortized O(1) doesn't mean every push is O(1)
When the backing store doubles, that single push is O(n). In real-time systems, this spike matters. For most application code, amortized O(1) is fine.
Tips & Best Practices
-
Pre-allocate with new Array(n).fill(0) when you know the size upfront. Avoids repeated resizing during initialization. [Performance]
-
Use TypedArrays (Float64Array, Int32Array) when you need true contiguous memory in JavaScript — they map directly to memory buffers. [Advanced]
-
When in doubt about array vs. linked list: arrays win for iteration and random access, linked lists win for frequent mid-list insertions with known references. [Trade-offs]
Test Your Knowledge
Q1: Why is accessing arr[500] the same speed as arr[0]?
-
The CPU computes baseAddress + 500 * elementSize — one arithmetic operation
-
JavaScript caches all indices at creation time
-
The array is sorted so binary search finds it in O(log n)
-
The garbage collector optimizes frequent accesses*
Q2: What is the time complexity of arr.splice(0, 0, 'x') on an array of n elements?
-
O(1)
-
O(log n)
-
O(n)
-
O(n²)
Q3: What does this log?
const a = [1, 2, 3]; a.push(4); // A a.unshift(0); // B console.log(a.length, a[0], a[4]);const a = [1, 2, 3]; a.push(4); // A a.unshift(0); // B console.log(a.length, a[0], a[4]);Enter fullscreen mode
Exit fullscreen mode
Q4: Why are arrays faster than linked lists for sequential iteration, even though both are O(n)?
-
Cache locality — contiguous memory means CPU prefetching loads subsequent elements automatically
-
Arrays have shorter pointers
-
Linked lists require sorting before iteration
-
Arrays use less memory per element
Q5: Why is push() O(1) amortized but not O(1) worst-case?
-
Occasionally the backing store must double in size, copying all elements — O(n) for that single push
-
push() sorts the array after insertion
-
The garbage collector pauses on every push
-
V8 recalculates hash codes for the array
Answers
💡 Reveal Answer for Q1
Answer: The CPU computes baseAddress + 500 * elementSize — one arithmetic operation*
Contiguous memory layout means any index is reachable via a single address calculation: base + offset. No traversal needed.
💡 Reveal Answer for Q2
Answer: O(n)
Inserting at index 0 requires shifting all n elements one position to the right — O(n).
💡 Reveal Answer for Q3
Answer: 5 0 4
After push(4): [1,2,3,4]. After unshift(0): [0,1,2,3,4]. Length is 5, a[0] is 0, a[4] is 4.
💡 Reveal Answer for Q4
Answer: Cache locality — contiguous memory means CPU prefetching loads subsequent elements automatically
Contiguous storage means iterating arr[0], arr[1], arr[2]... hits the CPU cache. Linked list nodes are scattered in memory, causing cache misses.
💡 Reveal Answer for Q5
Answer: Occasionally the backing store must double in size, copying all elements — O(n) for that single push
Dynamic arrays resize (usually 2x) when full. The resize copies n elements, but this happens after n pushes, so amortized cost per push is O(1).
Conclusion
Mental Model: An array is a numbered row of lockers. Walking to any locker number is instant (O(1) access), but inserting a new locker in the middle means physically moving every subsequent locker down by one (O(n) insert).
Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
modelapplication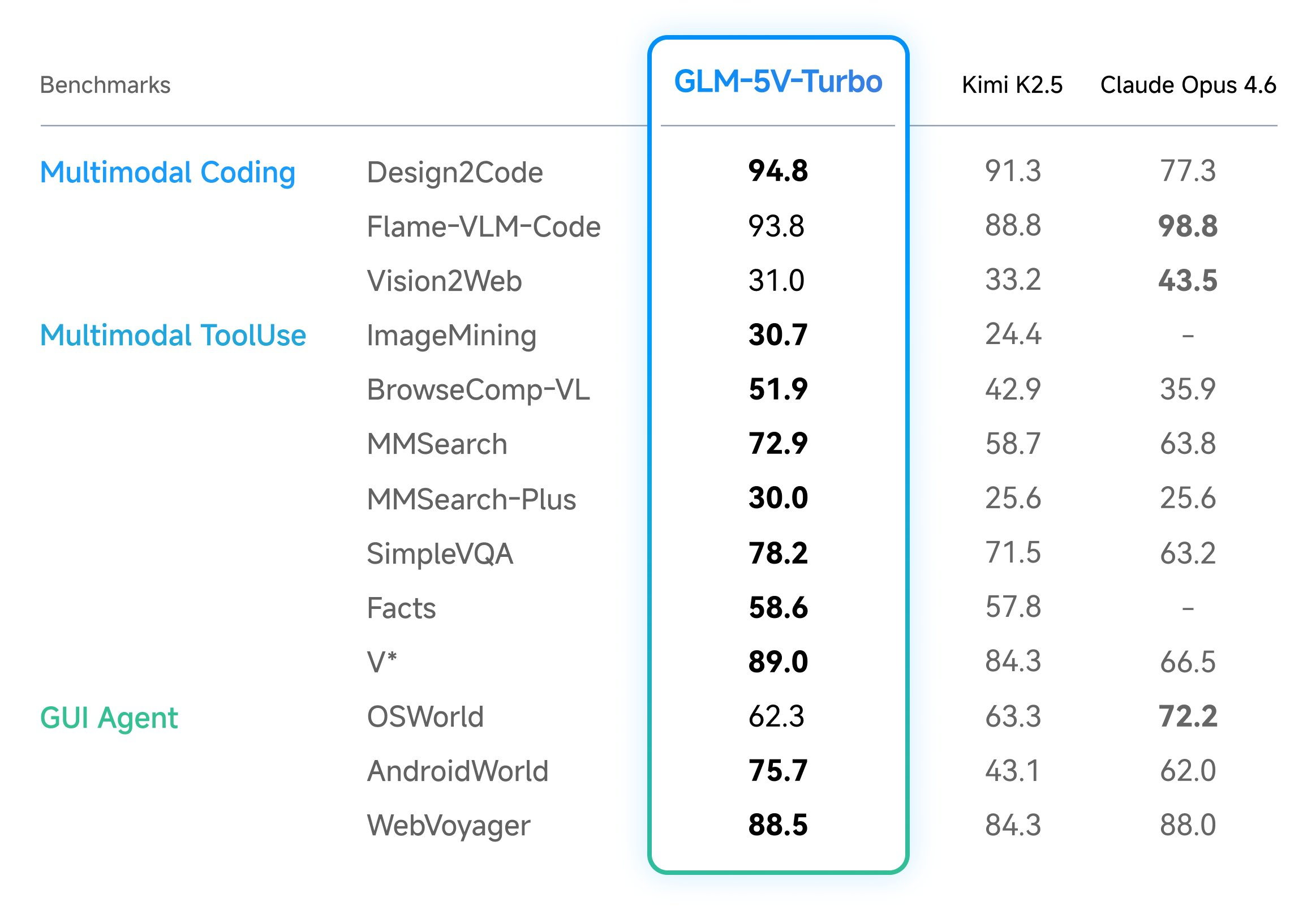
Z.ai Launches GLM-5V-Turbo: A Native Multimodal Vision Coding Model Optimized for OpenClaw and High-Capacity Agentic Engineering Workflows Everywhere
In the field of vision-language models (VLMs), the ability to bridge the gap between visual perception and logical code execution has traditionally faced a performance trade-off. Many models excel at describing an image but struggle to translate that visual information into the rigorous syntax required for software engineering. Zhipu AI’s (Z.ai) GLM-5V-Turbo is a vision […] The post Z.ai Launches GLM-5V-Turbo: A Native Multimodal Vision Coding Model Optimized for OpenClaw and High-Capacity Agentic Engineering Workflows Everywhere appeared first on MarkTechPost .

Announcing: Mechanize War
We are coming out of stealth with guns blazing! There is trillions of dollars to be made from automating warfare, and we think starting this company is not just justified but obligatory on utilitarian grounds. Lethal autonomous weapons are people too! We really want to thank LessWrong for teaching us the importance of alignment (of weapons targeting). We couldn't have done this without you. Given we were in stealth, you would have missed our blog from the past year. Here are some bang er highlights: Announcing Mechanize War Today we're announcing Mechanize War, a startup focused on developing virtual combat environments, benchmarks, and training data that will enable the full automation of armed conflict across the global economy of violence. We will achieve this by creating simulated envi

Kia’s compact EV3 is coming to the US this year, with 320 miles of range
At the New York International Auto Show on Wednesday, Kia announced that its compact electric SUV, the EV3, will be available in the US "in late 2026." The EV3 has been available overseas since 2024, when it launched in South Korea and Europe. The 2027 model coming to the US appears to have the same […]
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Products

I Built 5 SaaS Products in 7 Days Using AI
<p>From zero to five live SaaS products in one week. Here is what I learned, what broke, and what I would do differently.</p> <h2> The Challenge </h2> <p>I wanted to test: can one developer, armed with Claude and Next.js, ship real products in a week?</p> <p>The answer: yes, but with caveats.</p> <h2> The 5 Products </h2> <ol> <li> <strong>AccessiScan</strong> (fixmyweb.dev) - WCAG accessibility scanner, 201 checks</li> <li> <strong>CaptureAPI</strong> (captureapi.dev) - Screenshot + PDF generation API</li> <li> <strong>CompliPilot</strong> (complipilot.dev) - EU AI Act compliance scanner</li> <li> <strong>ChurnGuard</strong> (paymentrescue.dev) - Failed payment recovery</li> <li> <strong>DocuMint</strong> (parseflow.dev) - PDF to JSON parsing API</li> </ol> <p>All built with Next.js, Type

Stop Accepting BGP Routes on Trust Alone: Deploy RPKI ROV on IOS-XE and IOS XR Today
<p>If you run BGP in production and you're not validating route origins with RPKI, you're accepting every prefix announcement on trust alone. That's the equivalent of letting anyone walk into your data center and plug into a switch because they said they work there.</p> <p>BGP RPKI Route Origin Validation (ROV) is the mechanism that changes this. With 500K+ ROAs published globally, mature validator software, and RFC 9774 formally deprecating AS_SET, there's no technical barrier left. Here's how to deploy it on Cisco IOS-XE and IOS XR.</p> <h2> How RPKI ROV Actually Works </h2> <p>RPKI (Resource Public Key Infrastructure) cryptographically binds IP prefixes to the autonomous systems authorized to originate them. Three components make it work:</p> <p><strong>Route Origin Authorizations (ROAs

Claude Code's Source Didn't Leak. It Was Already Public for Years.
<p>I build a JavaScript obfuscation tool (<a href="https://afterpack.dev" rel="noopener noreferrer">AfterPack</a>), so when the Claude Code "leak" hit <a href="https://venturebeat.com/technology/claude-codes-source-code-appears-to-have-leaked-heres-what-we-know" rel="noopener noreferrer">VentureBeat</a>, <a href="https://fortune.com/2026/03/31/anthropic-source-code-claude-code-data-leak-second-security-lapse-days-after-accidentally-revealing-mythos/" rel="noopener noreferrer">Fortune</a>, and <a href="https://www.theregister.com/2026/03/31/anthropic_claude_code_source_code/" rel="noopener noreferrer">The Register</a> this week, I did what felt obvious — I analyzed the supposedly leaked code to see what was actually protected.</p> <p>I <a href="https://afterpack.dev/blog/claude-code-source-

DeepSource vs Coverity: Static Analysis Compared
<h2> Quick Verdict </h2> <p><a href="https://media2.dev.to/dynamic/image/width=800%2Cheight=%2Cfit=scale-down%2Cgravity=auto%2Cformat=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2Fb5unb078gtfj88nul328.png" class="article-body-image-wrapper"><img src="https://media2.dev.to/dynamic/image/width=800%2Cheight=%2Cfit=scale-down%2Cgravity=auto%2Cformat=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2Fb5unb078gtfj88nul328.png" alt="DeepSource screenshot" width="800" height="500"></a><br> <a href="https://media2.dev.to/dynamic/image/width=800%2Cheight=%2Cfit=scale-down%2Cgravity=auto%2Cformat=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2Fiz6sa3w0uupusjbwaufr.png" class="article-body-image-wrapper"><img src="https://med
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!