

Building a "Soft Sensor" for Cement Kilns: Predicting Control Levers with Python
<p>In the cement industry, the "Ustad" (Master Operator) knows that a kiln is a living beast. When the lab results for the Raw Meal come in, the operator has to balance the "Four Pillars" of control to ensure the clinker is high quality and the kiln remains stable.</p> <p>Wait too long to adjust, and you risk a "snowball" in the kiln or high free lime. This is where Machine Learning comes in. In this article, we will build a Soft Sensor using Python to predict the four critical control levers based on raw meal chemistry.</p> <p>The Four Pillars of Kiln Control<br> To keep a kiln in a steady state, we must manage four interconnected variables:</p> <p>Kiln RPM: Controls the material residence time.</p> <p>ID Fan Setting: Manages the draft and oxygen (the kiln's lungs).</p> <p>Feed Rate: The
In the cement industry, the "Ustad" (Master Operator) knows that a kiln is a living beast. When the lab results for the Raw Meal come in, the operator has to balance the "Four Pillars" of control to ensure the clinker is high quality and the kiln remains stable.
Wait too long to adjust, and you risk a "snowball" in the kiln or high free lime. This is where Machine Learning comes in. In this article, we will build a Soft Sensor using Python to predict the four critical control levers based on raw meal chemistry.
The Four Pillars of Kiln Control To keep a kiln in a steady state, we must manage four interconnected variables:
Kiln RPM: Controls the material residence time.
ID Fan Setting: Manages the draft and oxygen (the kiln's lungs).
Feed Rate: The amount of raw material entering the system.
Fuel Adjustment: The thermal energy required for the sintering zone.
The Architecture: Multi-Output Regression Because these four variables are physically dependent on each other (e.g., if you increase Feed, you usually must increase Fuel and RPM), we shouldn't predict them in isolation. We will use a Multi-Output Regressor with XGBoost.
Step 1: The Setup Python import pandas as pd import numpy as np from xgboost import XGBRegressor from sklearn.multioutput import MultiOutputRegressor from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.metrics import mean_absolute_error
1. Load your dataset
Features: LSF (Lime Saturation), SM (Silica Modulus), AM (Alumina Modulus), Moisture
Targets: RPM, ID Fan, Feed Rate, Fuel
df = pd.read_csv('kiln_process_data.csv')
X = df[['LSF', 'SM', 'AM', 'Moisture_Pct']] y = df[['Kiln_RPM', 'ID_Fan_Pct', 'Feed_Rate_TPH', 'Fuel_TPH']]
2. Train/Test Split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
3. Scaling (Important for industrial data ranges)
scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test) Step 2: Training the "Soft Sensor" We use the MultiOutputRegressor wrapper. This allows one model to handle all four targets while maintaining the statistical relationships between them.
Python
Initialize the base XGBoost model
base_model = XGBRegressor( n_estimators=500, learning_rate=0.05, max_depth=6, subsample=0.8, colsample_bytree=0.8 )
Wrap it for multi-output
soft_sensor = MultiOutputRegressor(base_model)
Fit the model to the kiln data
soft_sensor.fit(X_train_scaled, y_train)
Predictions
predictions = soft_sensor.predict(X_test_scaled) Step 3: Evaluation & "Ustad" Logic In the plant, accuracy isn't just a percentage; it's about staying within mechanical limits. We evaluate each lever individually:
Python targets = ['Kiln_RPM', 'ID_Fan_Pct', 'Feed_Rate_TPH', 'Fuel_TPH'] for i, col in enumerate(targets): mae = mean_absolute_error(y_test.iloc[:, i], predictions[:, i]) print(f"Mean Absolute Error for {col}: {mae:.4f}") Safety Guardrails (The "Control" Logic) Machine Learning models can sometimes suggest "impossible" values. In production, we wrap the model in a clipping function to respect the physical limits taught by the masters.
Python def get_operational_settings(raw_meal_inputs):
Scale inputs
scaled_input = scaler.transform(raw_meal_inputs) raw_pred = soft_sensor.predict(scaled_input)[0]
# Apply Safety Constraints safe_settings = { "Kiln_RPM": np.clip(raw_pred[0], 1.5, 4.2), # Max RPM 4.2 "ID_Fan": np.clip(raw_pred[1], 65, 95), # Draft range "Feed_Rate": np.clip(raw_pred[2], 200, 450), # TPH range "Fuel": np.clip(raw_pred[3], 15, 30) # Burner capacity } return safe_settings# Apply Safety Constraints safe_settings = { "Kiln_RPM": np.clip(raw_pred[0], 1.5, 4.2), # Max RPM 4.2 "ID_Fan": np.clip(raw_pred[1], 65, 95), # Draft range "Feed_Rate": np.clip(raw_pred[2], 200, 450), # TPH range "Fuel": np.clip(raw_pred[3], 15, 30) # Burner capacity } return safe_settingsEnter fullscreen mode
Exit fullscreen mode
Why This Matters Reduced Variability: No matter which operator is on shift, the model provides a consistent "baseline" adjustment based on the chemistry.
Energy Efficiency: Precision fuel and ID fan control directly reduce the heat consumption per kilogram of clinker.
Proactive Control: You move from reacting to lab results to predicting the necessary changes.
Conclusion Building a Soft Sensor for a cement kiln isn't just about the code; it's about translating chemical moduli into mechanical action. By using Python and Multi-Output Regression, we can digitize the "intuition" of the best operators and create a more stable, efficient plant.
Are you working on Industrial AI? Let’s discuss in the comments!
Python #DataScience #Manufacturing #IndustrialIoT #CementIndustry
DEV Community
https://dev.to/aminuddinkhan/building-a-soft-sensor-for-cement-kilns-predicting-control-levers-with-python-4001Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
modeltrainingproduct
Bring state-of-the-art agentic skills to the edge with Gemma 4
Google DeepMind has launched Gemma 4, a family of state-of-the-art open models designed to enable multi-step planning and autonomous agentic workflows directly on-device. The release includes the Google AI Edge Gallery for experimenting with "Agent Skills" and the LiteRT-LM library, which offers a significant speed boost and structured output for developers. Available under an Apache 2.0 license, Gemma 4 supports over 140 languages and is compatible with a wide range of hardware, including mobile devices, desktops, and IoT platforms like Raspberry Pi.
Google and Amazon: Acknowledged Risks, And Ignored Responsibilities
In late 2024, we urged Google and Amazon to honor their human rights commitments, to be more transparent with the public, and to take meaningful action to address the risks posed by Project Nimbus, their cloud computing contract that includes Israel’s Ministry of Defense and the Israeli Security Agency. Since then, a stream of additional reporting has reinforced that our concerns were well-founded. Yet despite mounting evidence of serious risk, both companies have refused to take action. Amazon has completely ignored our original and follow-up letters. Google, meanwhile, has repeatedly promised to respond to our questions. Yet more than a year and a half later, we have seen no meaningful action by either company. Neither approach is acceptable given the human rights commitments these compa

Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Products

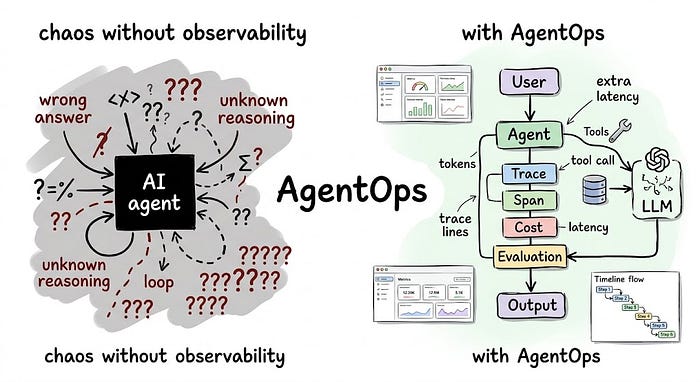
AgentOps: Your AI Agent Is Already Failing in Production. You Just Can’t See It
Last Updated on April 2, 2026 by Editorial Team Author(s): Divy Yadav Originally published on Towards AI. The practical guide to monitoring, debugging, and governing AI agents before they become a liability You shipped an AI agent. It worked in staging. Photo by authorFollowing the introduction, the article delves into the challenges faced by teams operating AI agents in production, emphasizing the inadequacy of traditional monitoring systems that fail to capture the nuanced failures of these agents. It introduces AgentOps as a necessary discipline for managing the lifecycle of AI agents, outlining five critical functions that enhance observability, control costs, evaluate performance, and ensure compliance in real-world applications. By sharing practical examples and potential pitfalls, t

A Plateau Plan to Become AI-Native
Last Updated on April 2, 2026 by Editorial Team Author(s): Bram Nauts Originally published on Towards AI. AI will not transform because it’s deployed – it will transform because the way of operating is redesigned. The tricky part? Transformations rarely fail at the start, they fail in the middle – when organisations try to scale. In a previous article I defined the concept of the AI-native bank. A bank where decisions, processes and customer interactions are continuously driven by AI. Since publishing that article, one question came up repeatedly: “How do we actually get there?” Before exploring that question, it is important to acknowledge something. The idea of AI-native organisations is still largely a promise. The potential of AI is enormous, but the long-term economics and risk profil
Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!