

Automated Functional Testing for Malleable Mobile Application Driven from User Intent
arXiv:2604.02079v1 Announce Type: new Abstract: Software malleability allows applications to be easily changed, configured, and adapted even after deployment. While prior work has explored configurable systems, adaptive recommender systems, and malleable GUIs, these approaches are often tailored to specific software and lack generalizability. In this work, we envision per-user malleable mobile applications, where end-users can specify requirements that are automatically implemented via LLM-based code generation. However, realizing this vision requires overcoming the key challenge of designing automated test generation that can reliably verify both the presence and correctness of user-specified functionalities. We propose \tool, a user-requirement-driven GUI test generation framework that i
View PDF HTML (experimental)
Abstract:Software malleability allows applications to be easily changed, configured, and adapted even after deployment. While prior work has explored configurable systems, adaptive recommender systems, and malleable GUIs, these approaches are often tailored to specific software and lack generalizability. In this work, we envision per-user malleable mobile applications, where end-users can specify requirements that are automatically implemented via LLM-based code generation. However, realizing this vision requires overcoming the key challenge of designing automated test generation that can reliably verify both the presence and correctness of user-specified functionalities. We propose \tool, a user-requirement-driven GUI test generation framework that incrementally navigates the UI, triggers desired functionalities, and constructs LLM-guided oracles to validate correctness. We build a benchmark spanning six popular mobile applications with both correct and faulty user-requested functionalities, demonstrating that \tool effectively validates per-user features and is practical for real-world deployment. Our work highlights the feasibility of shifting mobile app development from a product-manager-driven to an end-user-driven paradigm.
Subjects:
Software Engineering (cs.SE)
Cite as: arXiv:2604.02079 [cs.SE]
(or arXiv:2604.02079v1 [cs.SE] for this version)
https://doi.org/10.48550/arXiv.2604.02079
arXiv-issued DOI via DataCite (pending registration)
Submission history
From: Yuying Wang [view email] [v1] Thu, 2 Apr 2026 14:10:11 UTC (1,023 KB)
Sign in to highlight and annotate this article
Conversation starters
Daily AI Digest
Get the top 5 AI stories delivered to your inbox every morning.
More about
benchmarkannounceproduct
![[R] 94.42% on BANKING77 Official Test Split with Lightweight Embedding + Example Reranking (strict full-train protocol)](https://d2xsxph8kpxj0f.cloudfront.net/310419663032563854/konzwo8nGf8Z4uZsMefwMr/default-img-earth-satellite-QfbitDhCB2KjTsjtXRYcf9.webp)
[R] 94.42% on BANKING77 Official Test Split with Lightweight Embedding + Example Reranking (strict full-train protocol)
BANKING77 (77 fine-grained banking intents) is a well-established but increasingly saturated intent classification benchmark. did this while using a lightweight embedding-based classifier + example reranking approach (no LLMs involved), I obtained 94.42% accuracy on the official PolyAI test split. Strict Full train protocol was used: Hyperparameter tuning / recipe selection performed via 5-fold stratified CV on the official training set only, final model retrained on 100% of the official training data (recipe frozen) and single evaluation on the held-out official PolyAI test split Here are the results: Accuracy: 94.42%, Macro-F1: 0.9441, Model size: ~68 MiB (FP32), Inference: ~225 ms per query This represents +0.59pp over the commonly cited 93.83% baseline and places the result in clear 2n
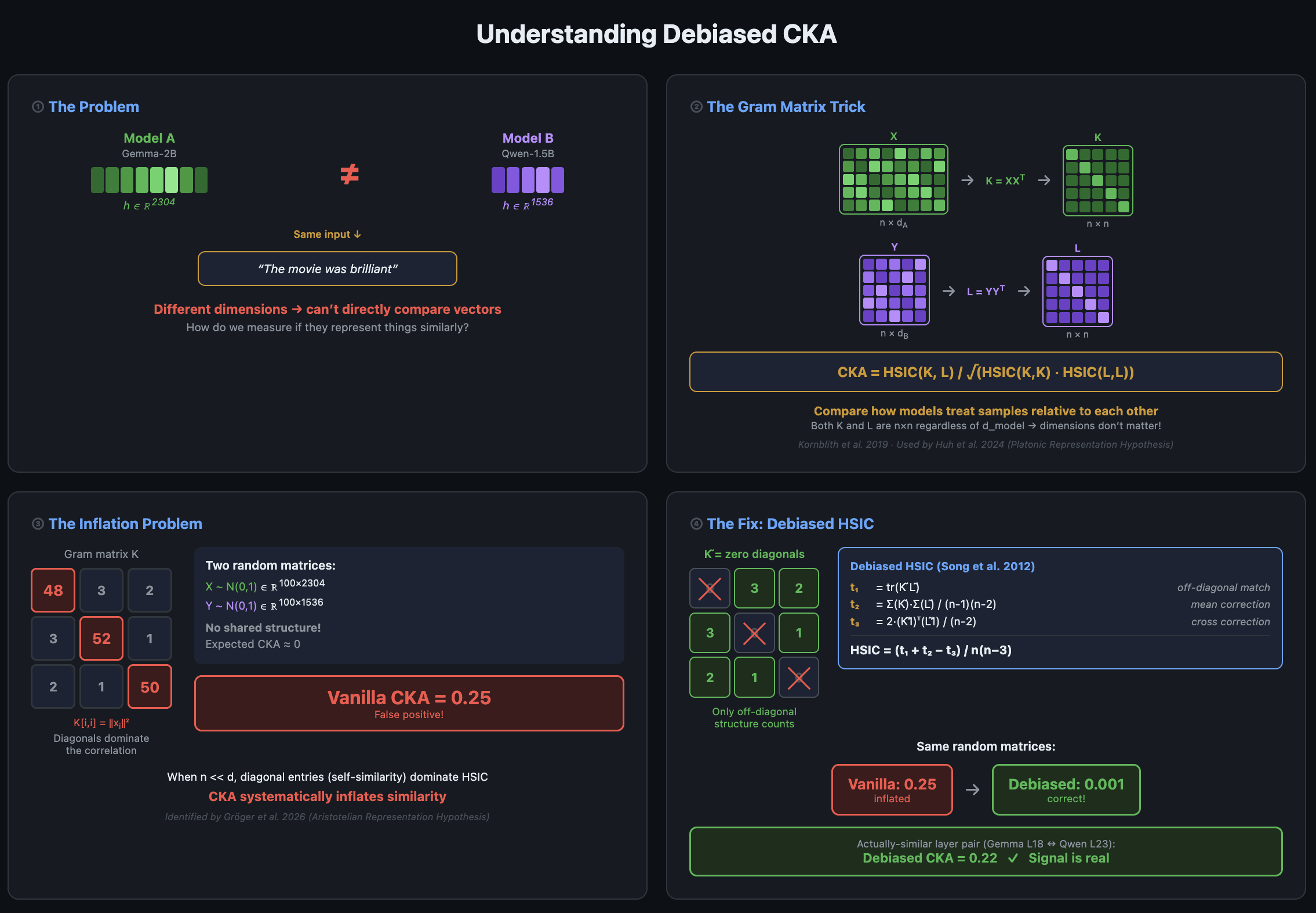
Cross-Model Activation Generalizability Isn't Strong (Yet)
TL;DR Tested activation similarities across different LLM families (Llama, Gemma, Qwen, Pythia) at small scale (1~3B) CKA Similarity : Cross-architectural activation similarity is statistically real, but weak. Within-family activations are much stronger (4~9x) Linear Transferability : Trained linear bridges for linear activation transfers for binary classification and next token prediction tasks. Within-family stands strong, cross-architecture yields better than random guessing, but not strong enough to be practically useful. Bottom Line : Shared structure across cross-architectures : broad linguistics / semantics only for now. Not enough for fine grained auditing tools. Code can be found here . This is my first interpretability research project, coming from a different field. I'm about 4
Knowledge Map
Connected Articles — Knowledge Graph
This article is connected to other articles through shared AI topics and tags.
More in Products


A look at Catches and other startups that are offering AI tools to let shoppers visualize fit and style before buying clothes, aiming to curb online returns (Elsa Ohlen/CNBC)
Elsa Ohlen / CNBC : A look at Catches and other startups that are offering AI tools to let shoppers visualize fit and style before buying clothes, aiming to curb online returns It pinches here; drags there; the draping is wrong. These are some of the examples of the feedback a new crop

Discussion
Sign in to join the discussion
No comments yet — be the first to share your thoughts!